Ça se passe au moment où la tartine beurrée entre en contact avec le café brûlant. Un ronronnement s’échappe du poste de radio. Une voix familière qui chevrote un peu, un phrasé impeccable qui franchit les « premièrement », les « deuxièmement » et les « mais également » sans jamais trébucher. Le texte, lui, glisse sans cahot d’une conférence genevoise à une réunion du G7, en passant par Bruxelles et ses sommets de la dernière chance.
Une chronique quotidienne depuis 1991
Bernard Guetta, 64 ans, est « un majestueux monument à dômes et à coupoles […] installé dans le paysage matinal », s’amusait Daniel Schneidermann. S’il le taquine, le fondateur d’Arrêt sur images voit aussi en lui l’un des rares journalistes qui « dans chaque événement microscopique cherchent par réflexe les racines profondes, les lointaines conséquences, bref la perspective ».
Le chroniqueur a rejoint France Inter en 1991 après une carrière déjà longue et tient depuis la chronique Géopolitique chaque matin, du lundi au vendredi à 8h19. Ce passage obligé de la matinale est inscrit dans la routine des auditeurs, sur le mode « déjà Guetta, faut y aller, Matteo va être en retard à l’école ».
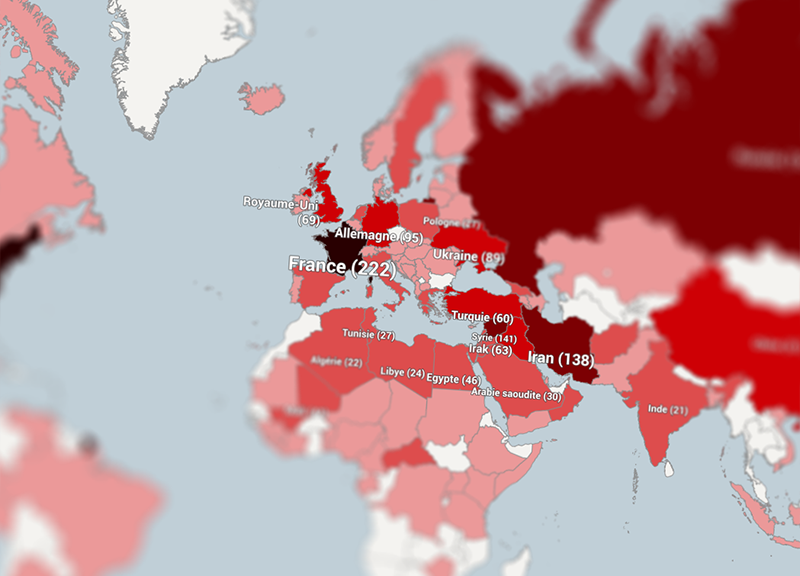
Les pays les plus cités dans la chronique Géopolitique de France Inter
| 0 | 1–10 | 10–50 | 50–100 | 100–200 | +200 |
|---|---|---|---|---|---|
Cliquez ou tapotez sur un pays pour plus d’infos, double-cliquez ou pincez pour zoomer.
Mais à quoi ressemble la carte du monde que Guetta raconte à près de 4 millions de Français mal réveillés ?
C’est à cette question que j’ai tenté de répondre en analysant 520 chroniques publiées sur le site de France Inter entre août 2012 et mai 2015 – pour ceux que ça intéresse, je reviens sur les outils utilisés dans un autre article de ce site.
Un tiers de plus que le Nouveau Testament
Près de trois saisons de chroniques pour un imposant corpus de plus de 300 000 mots (pour vous donner une idée, ça fait un tiers de plus que le Nouveau Testament), soit 1,6 million de signes ou encore plus de 1 000 feuillets.
La carte en haut de cette page montre le résultat de ses recherches (contactez-moi ou laissez un commentaire si vous avez remarqué une erreur ou une bizarrerie). Je les ai également rassemblées sous forme de classements.
En se promenant sur la planète de Bernard Guetta, on remarque bien sûr la domination des Etats-Unis, cités dans un près d’une chronique sur deux. Mais la Russie, le Proche-Orient et le Moyen-Orient sont aussi bien servis par le chroniqueur. Logique, vu l’actualité de ces trois dernières années en Ukraine, en Syrie et dans le reste du monde arabe.
Les pays émergents sont moins bien lotis : la Chine n’a été citée que 61 fois, et l’Inde (21 ) comme le Brésil (6) ne semblent guère passionner le chroniqueur.
Même relatif désintérêt pour l’Afrique, surtout si on met de côté les pays où la France est intervenue militairement (Libye, Mali, Centrafrique) – le Nigéria, devenu pourtant la première économie d’Afrique n’est cité que sept fois. Ou pour l’ensemble Amérique latine, malgré les remuants dirigeants du Venezuela, de la Bolivie et de l’Equateur.
« Eclairer les événements, les hiérarchiser »
Loin des yeux, loin du cœur de Guetta ? L’Indonésie, malgré ses 250 millions d’habitants, n’est mentionnée qu’une seule fois, l’Australie et l’Afrique du Sud trois fois seulement.
A l’inverse, de petits pays sont l’objet d’une plus grande attention, comme le Liban, présent dans 35 chroniques, l’Arménie (7) et bien sûr le Vatican (7).
Devant ces chiffres parfois étonnants, Bernard Guetta m’explique qu’il n’est « pas un universitaire », qu’il n’a pas vocation « à passer en revue les plus de 200 pays présents l’ONU », mais qu’il entend, en bon journaliste, « éclairer les événements les plus marquants et les hiérarchiser ».
Le chroniqueur explique ne pas chercher, au fil de ses interventions, un équilibre entre les différentes régions du monde. « C’est l’actualité qui commande », résume-t-il, ajoutant :
« Je vous mets en garde contre la tentation de tirer des conclusions basées seulement sur le nombre d’occurrences, pour moi ce n’est pas pertinent. »
Thaïlande, Maroc, Birmanie : rien
Mais ce qui m’a le plus surpris, ce sont les trous du gruyère : en effet, la liste des pays qui n’ont jamais cités en plus de 500 chroniques comprend quelques poids lourds.
C’est le cas de la Thaïlande, qui a pourtant connu, sur la période étudiée, une crise politique majeure débouchant sur une reprise en main du pays par l’armée. Mais aussi de la Birmanie, dont le régime donne des signes d’ouverture depuis la libération d’Aung San Suu Kyi en 2010.
Plus frappant encore, le cas du Maroc, où Guetta a pourtant passé une partie de sa jeunesse – l’Algérie voisine est elle mentionnée 22 fois. Ces absences ne perturbent cependant pas l’intéressé :
« Tout dépend de la période que vous étudiez. Il n’était pas illogique que je n’aie pas parlé du Maroc ces derniers temps, il n’y avait pas d’actualité importante dans ce pays.
La brouille avec la France [après que le chef du contre-espionnage marocain Abdellatif Hammouchi a été convoqué par un juge français lors d’un voyage à Paris, ndlr] n’a pas duré très longtemps.
J’en aurais peut-être parlé si personne ne l’avait fait, mais j’ai considéré que ça ne faisait pas le poids, à ce moment-là, face à d’autres événements. »
C’est la limite de mon petit travail : comme tous les journalistes, Guetta parle d’abord des pays dont on parle, ceux qui sont « dans l’actualité », aussi mouvante soit la définition qu’on donne à ce mot. Mais je reste convaincu que sur une si longue période et un si grand nombre de textes, mon exploration du « monde de Bernard Guetta » a malgré tout du sens.
Plus un pays est riche, plus il est cité
Si on met de côté l’actu, quel critère peut expliquer qu’un pays s’impose ou non sur cette drôle de mappemonde ? En croisant ces relevés avec les données de la Banque mondiale, j’ai cherché des corrélations. J’ai fait chou blanc avec la superficie, la population, le PIB par habitant ou le nombre de décès dans des conflits armés.
En revanche, plus un pays est globalement riche, et plus il a de chances d’être cité dans les chroniques de Guetta – pour les matheux, le coefficient de corrélation est de 0,64. Ce n’est pas illogique : une économie importante va souvent de pair avec des dépenses militaires significatives et une diplomatie plus active.
La liste des personnalités les plus citées réserve elle peu de surprises, même si on notera que Jacques Delors et Charles de Gaulle font de fréquentes apparitions – le premier est plus souvent cité qu’Hugo Chavez.
Enfin, je me suis aussi intéressé au contexte dans lequel ces pays et ces personnalités étaient citées, grâce à un logiciel de « lexicométrie ». J’ai cherché par exemple les adjectifs les qualifiant, notamment ceux qui peuvent dénoter un jugement de valeur voire un parti-pris (par exemple, « populiste » pour Chavez ou « intransigeant » pour Poutine).
L’Europe et le « divorce » des Européens
On peut voir ainsi que Guetta associe très souvent le mot « Europe » (et ses dérivés) au mot « divorce », dans des phrases comme : « Le divorce croissant entre les Européens et l’Europe menace jusqu’à l’idée même d’unité européenne. » Européiste convaincu, il a fait activement (outrageusement pensent certains, comme Acrimed) campagne pour le oui au référendum sur le traité constitutionnel de 2005.
Mais ces quelques coup de sonde n’ont pas donné grand chose : les « cooccurrences » (soit les mots qu’on relève souvent au voisinage d’un autre dans le texte) détectées m’ont semblé assez neutres – en y passant plus de temps, un spécialiste ferait peut-être davantage de trouvailles.
La preuve d’une prudence très diplomatique dans le choix des formulations ? Bernard Guetta explique en tout cas « sa très grande méfiance à l’égard de mots qui ne veulent plus rien dire, comme islamiste » : « Je préfère utiliser un langage plus précis, un mot qui décrit ce qui se passe. »
Mis à jour le 8 mai à 8h20. Erreur d’unité dans le classement et la carte corrigée, merci à @florenchev de l’avoir signalée.
Mis à jour le 11 mai à 8h30. Erreur dans le nombre de citations d’Erdogan, merci à Sibel Fuchs de l’avoir signalée sur Facebook.
Illustration utilisée sur la page Facebook Dans mon labo d’après photo David Monniaux (CC BY-SA)