Vous avez été nombreux à montrer votre intérêt pour le tableau de bord des obsessions, marottes et zones d’ombre des médias que j’ai publié début février. Je vais donc continuer de le compléter et de l’améliorer dès que j’aurais un peu de temps devant moi, et listé dans ce post les derniers changements.
Vendredi 5 octobre
Après une série de tests, affichage des graphiques montrant l’évolution du traitement d’un thème depuis un mois.
Lundi 6 août
La mise à jour des informations ne se faisait plus, la faute à un problème sur le flux RSS d’un des médias. Problème désormais réparé.
Samedi 10 février
Une dizaine de médias supplémentaires sont désormais étudiés : Courrier international, L’Equipe, Les Echos, La Tribune, Challenges, Capital, Reporterre, L’imprévu, Bastamag, Contexte, StreetPress, The Conversation.
Dans la liste des entités, le classement actuel et son évolution par rapport à la période précédente est indiqué, à la manière du Top 50.
Le script qui récupère les titres et descriptions des articles publiés par chaque média (via leur flux RSS) passe désormais une fois par heure, et non plus trois fois par jour, pour ne rien rater sur les sites qui publient beaucoup de contenu comme 20 minutes.
L’adresse du flux RSS utilisé pour L’Express était erronée et a été corrigée.
La qualité du corpus utilisé pour l’analyse a été beaucoup améliorée : problèmes d’encodage résolus (Le Monde, Vice…), balises HTML mieux filtrées (Mashable…), suppression des retours chariots, retours à la ligne et tabulations.
Le corpus ne contient plus que les 150 premiers caractères de la description de chaque article publié, afin de ne pas défavoriser dans l’analyse les sites qui ne fournissent qu’une description très courte dans leur fil RSS, comme Le Point.
Trois médias ne peuvent être étudiés : Buzzfeed (contenus en anglais dans le fil RSS), Valeurs actuelles (fil RSS illisible), Télérama (pas de fil RSS disponible).
C’est sans doute le projet le plus ambitieux et le plus complexe que j’aie mené à bien depuis que j’ai lancé Dans mon labo il y a bientôt quatre ans. Il m’a fallu pas mal d’après-midi pluvieux et de jours fériés blafards pour terminer le tableau de bord qui liste les sujets les plus présents dans les sites d’actualité français.
Il est devenu possible grâce aux progrès que j’ai réalisés en Python, un langage de programmation prisé des datajournalistes. De mon côté, j’ai dû sérieusement m’y mettre courant 2017, notamment pour afficher en direct les résultats des élections législatives au sein de la carte interactive que j’ai préparée pour Contexte.
Pour explorer les flux XML mis à disposition par le ministère de l’Intérieur le soir des scrutins, j’ai trouvé en Python, avec sa syntaxe accessible et ses multiplies librairies disponibles, un partenaire idéal. (Mais il est aussi possible de faire ça très bien avec d’autres solutions, comme R.)
Et ces connaissances m’ont ouvert de nouveaux horizons, notamment ceux de la reconnaissance automatisée d’entités nommées. Un domaine qui, m’a-t-on expliqué, a beaucoup progressé grâce au patient travail de description et de classement réalisé par les contributeurs de Wikipedia.
J’ai d’abord travaillé, toujours pour Contexte, sur les thématiques les plus présentes dans le discours des députés pour enrichir le trombinoscope de l’Assemblée nationale que le site propose à ses abonnés. C’est alors que m’est venue l’idée de proposer une démarche comparable, mais avec les médias en ligne.
1. Scraper les flux RSS des sites d‘actu avec Python
J’ai listé, dans une Google Sheet, les sites que je souhaitais étudier, en renseignant pour chacun l’adresse de son flux RSS principal.
Mon script de scraping (dispo pour les curieux) commence par récupérer cette liste, et va chercher dans chaque flux le titre et la description (le chapô ou le début du texte) de chaque article. Il récupère aussi sa date de publication, et enregistre le tout dans un fichier Json dédié à chaque site.
Tous les flux RSS n’étant pas construits de la même façon, il a fallu prendre en compte les différents cas de figure : ainsi, le résumé de l’article se trouve dans un élément qui peut être nommé « description », « summary », « content »…
2. Créer un corpus de textes et le faire analyser par TextRazor
La suite de ce script va concaténer ensemble les titres et résumés de chaque article publiés dans une période donnée pour en faire un seul et même texte.
Ce corpus va ensuite être envoyé à TextRazor, via la librairie Python que met à disposition ce service d’analyse sémantique. Ce dernier est gratuit jusqu’à 500 requêtes par jour, un quota largement suffisant pour ce projet.
Parmi les services équivalents, TextRazor a un autre avantage : non seulement son outil d’extraction des entités nommées renvoie la liste des thématiques détectées au sein du corpus soumis, mais il fournit aussi pour chacune un score de relevance (« pertinence », que j’ai finalement traduit en « présence » dans mon tableau de bord).
Ainsi, s’il détecte les mots « GPA », « gestation pour autrui » ou « mère porteuse » dans un texte, Textrazor réunit ses expressions dans une seule thématique (en général le titre de la notice Wikipedia dédiée). Et donne à cette dernière une note, de 0 à 1, selon que l’entité lui semble plus ou moins pertinente dans le texte fourni.
C’est à la fois la force et la faiblesse de ma méthode : ce scoring me permet de générer les multiples classements, mais je n’ai pas « la main » sur son élaboration.
Malgré quelques mauvaises surprises, l’observation des résultats obtenus m’a toute fois rassuré : Le Parisien est en général le média où le thème « Paris » est le plus présent ; on retrouve souvent « Jean-Luc Mélenchon » bien classé dans les résultats de Politis ; Sputnik et RT France sont bien placés au classement pour le thème « Vladimir Poutine ».
4. Héberger les scripts sur un serveur chez PythonAnywhere
Cette partie-là du chantier serait une promenade de santé pour un développeur back-end même débutant. A un journaliste bidouilleur comme moi, elle a pris pas mal de temps et d’énergie.
Une fois le script Python décrit ci-dessus terminé, je ne pouvais pas l’exécuter moi-même plusieurs fois par jour sur mon ordinateur afin de disposer de données toujours fraîches pour alimenter un éventuel tableau de bord.
Sur les conseils d’amis développeurs, j’ai regardé plusieurs offres d’hébergement comme Amazon Web Services ou Google Cloud Platform, mais la longueur des procédures d’installation et des tutoriels proposés m’a vite refroidi. Je me suis rabattu sur Python Anywhere. un service peu onéreux et qui s’est révélé mieux adapté à un noob comme moi.
Même avec cette solution, je suis passé par mal, de guides d’utilisation, de pages d’aide et de questions Stack Overflow avant d’arriver mes fins : faire tourner mon script de scraping plusieurs fois par jour.
4. Créer le tableau de bord en front à partir d’un fichier Json optimisé
Une fois toutes ces listes de thématiques récupérées et enregistrées dans le fichier Json de chaque média, un autre script Python, lui aussi hébergé sur PythonAnywhere, va préparer un fichier Json commun et de taille réduite.
Ce dernier sera récupéré, au moment où le tableau de bord publié Dans mon labo se charge, par votre navigateur. Au final, c’est donc Chrome, Firefox ou Edge qui va construire l’infographie à l’intérieur de la page.
Je ne détaillerais pas sur ce travail de développement front-end, classique combinaison de HTML, de CSS et de Javascript, mais si vous avez des questions sur cette partie, je serai ravi d’y répondre !
A ce stade, la principale difficulté pour moi a été de s’assurer que le chargement des données puis la construction de l’infographie se fasse dans un délai raisonnable : lors des premières étapes, le tout prenait parfois une bonne dizaine de secondes, ce qui es rédhibitoire.
Pour chaque média, j’ai choisi de ne pas intégrer une thématique si son score était inférieur à un certain seuil (en ce moment, 0,4/1), et de n’afficher une thématique dans la liste principale que si elle était présente dans au moins quatre médias.
Il m’a fallu pas mal d’allers-retours entre scripts Python sur le serveur et code Javascript dans le navigateur pour réduire ce délai et obtenir une expérience suffisamment fluide, mais il reste sans doute pas mal d’optimisation possible.
5. Préparer la suite avec des analyses hebdomadaires et mensuelles
Comme beaucoup l’ont fait remarquer dès la publication du tableau de bord, les résultats seront intéressants à observer dans le temps, au-delà de la photographie actuelle (les sept derniers jours). Mon script réalise déjà des analyses hebdomadaires et mensuelles, qui ne sont pas affichées mais que j’espère utiliser quand j’aurais davantage de recul. (Edit le 5 octobre : des graphiques s’affichent désormais pour chaque thématique, j’y reviens dans un thread sur Twitter)
Voilà ! Je suis en tout cas curieux de savoir vos remarques, critiques ou propositions d’amélioration dans les commentaires de ce post ou bien, pour les timides, dans un message privé.
Mis à jour le 2/2 à 10h15. Précision sur les seuils (point 4) et point 5 ajouté.
Comme souvent, le travail que j’ai réalisé pour ma petite enquête sur la France de la VO et celle de la VF met en jeu toute une série d’outils que j’ai découvert au fil des ans, qu’il s’agisse de scraping, de jointures de tables ou de représentation par anamorphoses. L’ensemble des données dont je me suis servi est disponible dans une Google Sheet.
Je vais en décrire les différentes étapes, ce qui peut être utile si vous souhaitez vous lancer dans un chantier comparable. N’hésitez pas à mettre votre grain de sel dans les commentaires.
1. Récupérer la liste des séances avec un scraping en deux étapes avec Outwit Hub
Pour commencer, il fallu que je me constitue une base contenant l’ensemble des salles de cinéma de France. Par chance, le site Cinefil propose des pages listant tous les cinés d’un département (par exemple, ceux situés dans l’Ain).
J’ai d’abord généré automatiquement une URL pour chaque département sur cinefil.com dans Google Sheet. J’ai ouvert cette première liste dans Outwit Hub, un logiciel de scraping qui m’a permis de rassembler une liste de 1 409 salles. Pour chacune, j’ai aussi récupéré l’URL de sa page sur cinefil.com.
Sur ces 1 409 URL, j’ai fait passer un second scraper, afin de récupérer la liste des films diffusés dans chaque salle sur une journée, avec les horaires des séances et la version diffusée (VF ou VO). J’ai obtenu ainsi une liste de 14 423 films et de 20 182 séances.
2. Déterminer la langue de tournage dans chaque film avec OMDB
Après quelques heures de travail, je me suis aperçu d’une chose toute bête mais qui m’avait échappé : sur Cinefil, les séances des films en langue française sont indiquées « en VF », ce qui ne permet pas de les différencier automatiquement des films en langue étrangère diffusés en VF…
Il a donc fallu que j’établisse une liste des 982 films différents diffusés sur toute la France ce jour-là (le 28 avril), et que je trouve un moyen de déterminer, pour chacun d’entre eux, s’il s’agit à l’origine d’un film tourné en langue française ou en langue étrangère.
L’API Omdb m’a permis de récupérer cette information dans un bon nombre de cas, par l’intermédiaire de Cloud Ignite, un module complémentaire de Google Sheet particulièrement pratique.
Pour le reste, j’ai réalisé des croisements – par exemple, un film qui n’est diffusé qu’en VO sur toute la France ne peut être qu’un film en langue étrangère – et des déductions – par exemple, une coproduction France/Suisse/Belgique a de bonnes chances d’être tournée en français.
Ce tri s’est révélé fastidieux et le résultat n’est pas garanti sans erreurs, mais j’ai estimé sa fiabilité suffisante pour continuer à avancer, en mettant de côté tous les films en langue française.
3. Géolocaliser chaque salle de cinéma avec ezGecode
J’avais déjà récupéré l’adresse et le code postal de chaque cinéma sur sa page Cinefil. Pour en déduire sa latitude et sa longitude, j’ai utilisé un autre module complémentaire de Google Sheet, ezGeocode.
La grande majorité des salles a ainsi été géolocalisée automatiquement et avec une très bonne fiabilité, et j’ai réussi à placer le reste grâce à des recherches manuelles dans Google Maps.
4. Déterminer le code commune pour chaque salle de cinéma
Afin de « marier » la base que je me suis ainsi constituée avec les données démographiques fournies par l’Insee ou les résultats électoraux disponibles sur le site du ministère de l’Intérieur, il me fallait déterminer le code Insee de la commune où se trouve chacun des cinémas de ma liste.
J’ai pu le faire grâce à une table de correspondances et à la base officielle des codes postaux, toutes deux disponibles sur Data.gouv.fr. Une série de recherches verticales plus tard, j’avais pour chaque salle de cinéma des informations comme la population de la ville, le taux de pauvreté, le vote Macron…
Des tableaux croisés dynamiques m’ont ensuite permis de consolider les résultats pour chacune des 278 localités françaises pourvues d’au moins une salle de cinéma (avec au moins une séance programmée ce jour-là), puis pour chaque département.
5. Réaliser les deux cartes interactives avec Carto
J’ai ensuite préparé deux séries de données, l’une avec toutes les salles où la part de la VO est majoritaire (#teamvo), et l’autre avec les salles plutôt VF (#teamvf).
J’ai créé deux cartes basées sur ces jeux dans Carto, et j’ai ajouté dans chacune d’elle un calque supplémentaire, avec les contours de chaque département et une couleur en fonction de la part de la VO ou de la VF à cette échelle.
J’ai passé pas mal de temps à chercher des réglages satisfaisants pour la taille des cercles, les nuances de couleurs ou encore la répartition des départements en cinq catégories (choix des intervalles).
6. Réaliser les cartes anamorphosées avec Qgis et Scapetoad
J’avais déjà utilisé les anamorphoses (cartograms en anglais) pour une série de cartes du monde tel que le voient les médias français qui avait tapé dans l’œil de pas mal d’observateurs. J’avais envie de commencer mon article avec ce type de visiuels, que je trouve facile à appréhender même pour des lecteurs peu friands d’infographies.
J’ai ouvert ce fichier dans l’éditeur de cartes Qgis afin d’associer à chaque département le nombre de séances en VO et en VF pour un million d’habitants.
C’est sur la base de ces deux données que j’ai réalisé les déformations de la carte de France dans ScapeToad, un petit utilitaire dédié à la création d’anamorphoses.
7. Créer une série de graphiques dans Datawrapper
Pour terminer, j’ai repris une dernière fois mes données pour isoler une série de chiffres de synthèse afin de créer les graphiques de synthèses qui figurent à la fin de l’article, en reprenant les codes couleur.
Ça fait partie de ces combats qui divisent les Français en deux camps irréconciliables. Comme la guerre sans merci du « pain au chocolat » et de la « chocolatine », ou le conflit séculaire entre la tartine au beurre salé et celle au beurre doux.
De même, il y a ceux qui ne jurent que par la version originale sous-titrée (VO) – quitte à passer son temps à lire les sous-titres plutôt qu’à profiter de l’action et des dialogues – et ceux qui ne peuvent pas vivre sans la version française (VF) – quitte à subir des traductions et des doublages pas toujours parfaits.
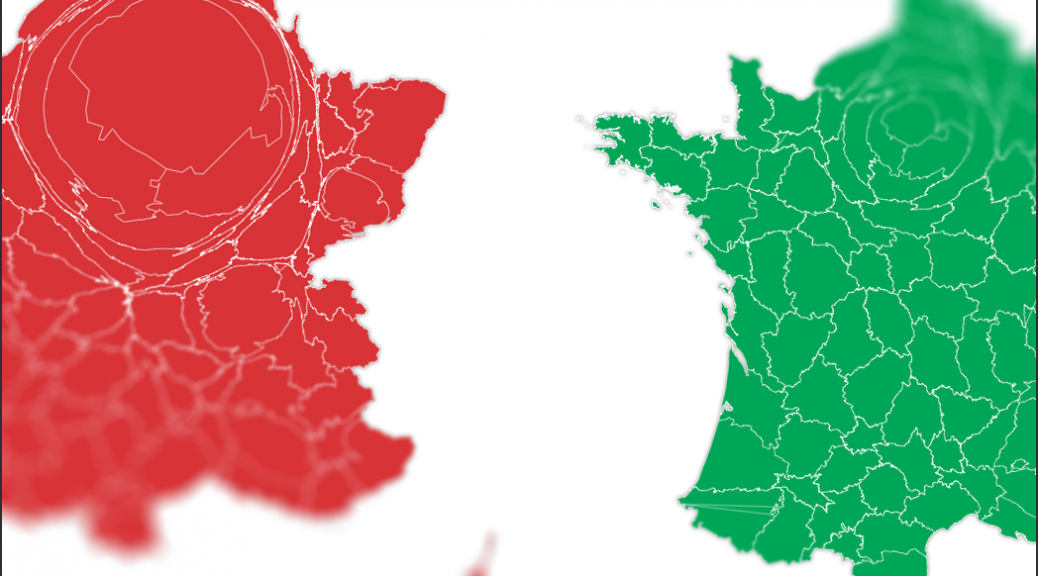
Histoire de frustrer un peu tout le monde, les cinémas ne proposent pas forcément les deux versions. Sur les deux anamorphoses en haut de cet article, plus un département est gros et plus ses habitants se voient proposer de séances en VO (à gauche, en rouge) ou de la VF (à droite, en vert).
Sur une journée, 20 182 séances de cinéma dans 1 400 salles
Pour les réaliser, j’ai récupéré, grâce à un scraper, l’intégralité des séances disponibles sur un site spécialisé pour la journée du 28 avril 2017. Soit plus de 20 182 séances, dans plus de 1 400 cinémas de France et de Navarre, projetant un total de 981 films différents.
Parmi ces derniers, j’en ai identifié 549 en langue étrangère (non sans mal, comme je l’explique dans un autre post sur site, où je reviens sur la méthode utilisée) pour un total de 14 223 séances, dont 2 964 en VO.
Dans certaines régions, la VO est réservée aux petites salles de centre-ville ou aux cinémas art et essai. Mais certains réseaux de multiplexes programment aussi un nombre important de séances en VO, comme UGC.
Si on passe à l’échelon des villes, c’est bien sûr à Paris que sont proposées le plus de séances en VO. Mais la banlieue et la province se défendent, avec Montreuil, Biarritz et Hérouville-Saint-Clair en tête devant la capitale si on prend compte la part totale des séances en VO.
A l’inverse, il y a des coins de France où on vous recommande pas de déménager si vous êtes #teamvo. Dans cinq départements, aucune séance en VO n’était proposée dans la journée :
l’Ariège
la Creuse
la Haute-Saône
l’Indre
l’Orne
Les villes avec VO et les villes avec VF
Mais pourquoi les cinémas d’une ville proposent-ils de la VO alors que ceux de la ville d’à côté se contentent de la VF ? Le goût pour la VO est lié à la richesse des habitants, à leur niveau d’éducation, où bien à leur choix politique ?
Sur les 1 133 localités étudiées, plus de 65% ne proposaient aucune séance en VO dans leurs salles de cinéma. Pour explorer mes données, j’ai donc réparti la liste en deux deux camps : les villes avec VO et les villes sans VO.
J’ai ensuite associé mes résultats à une série de statistiques de l’Insee, à commencer par la population (en 2014). Sans surprise, ce sont dans les localités les plus peuplées qu’on a le plus de chances se trouver des séances en VO.
Ça semble logique : comme la majorité des Français préfère la VF, proposer de la VO n’est commercialement intéressant que si la salle se trouve dans une zone suffisamment peuplée pour qu’on y trouve un nombre suffisant d’amateurs de versions sous-titrées.
Dans les deux camps, le niveau de vie médian est proche. On peut faire l’hypothèse que la VO n’est pas « un truc de riches »…
… ce que semble confirmer la comparaison du taux de pauvreté médian des deux séries de villes.
En revanche, si on s’intéresse à la part de la population ayant suivi des études supérieures, la différence est nette.
Je vois au moins une causalité possible à cette corrélation : plus on étudie, plus on est à l’aise avec la lecture, et moins on est gêné quand on doit passer du temps à lire les dialogues en bas de l’écran. Ce qui pourrait inciter les gérants de salle de la localité concernée à privilégier les copies en VO.
J’ai aussi croisé mes données avec les résultats du premier tour de la présidentielle 2017. Les villes sans VO ont tendance à voter davantage pour Le Pen et moins pour Macron et Mélenchon que les autres. Si la présidentielle ne s’était jouée que dans les villes avec VO, Mélenchon aurait été qualifié pour le second tour.
Voilà ! Evidemment, ce travail est très parcellaire, et la méthode que j’ai utilisée sûrement contestable. Je ne suis pas spécialiste de l’étude des pratiques culturelles, et je ne sais pas si cette grande fracture française a fait l’objet d’enquêtes plus poussées. [ajout le 27/7 à 17h20 : Vodkaster a fait un point assez complet sur le sujet en 2016]
Je serais en tout cas ravi d’en savoir plus, donc n’hésitez pas à descendre donner votre avis un peu plus bas dans les commentaires, et à aller explorer ces données, qui sont disponibles dans une Google Sheet.
Corrigé le 21/7 à 10h20. Inversion des barres dans les graphique niveaux de vie et part des diplômés du supérieur.
Mis à jour le 21/7 à 11h45. Ajout du graphique consacré aux réseaux de multiplexes.
Corrigé le 1/10 à 21h10. Inversion des barres dans le graphique population.
C’est sans doute l’expérience publiée sur ce site qui m’a donné le plus de fil à retordre. Il a fallu passer par de nombreuses et fastidieuses étapes pour arriver à la publication de la série de cartes du monde tel que le voient les médias français Dans mon labo.
Mais je suis content du rendu un peu arty de ces anamorphoses – j’ai emprunté l’idée et une partie de la méthode à Altermondes, qui en avait réalisé une à l’occasion de sa campagne de crowdfunding.
1. Scraper les résultats de recherche Google en Python
C’était la première fois que je réalisais un travail d’extraction automatique de données en concevant un script dans un langage de programmation plutôt qu’en utilisant un logiciel disposant d’une interface graphique, comme Outwit Hub.
Je me suis servi de Scrapy, un outil qui m’a beaucoup facilité la tâche, mais que je n’ai pas réussi à installer sur mon Mac (la faute à El Capitan, semble-t-il) : il a fallu ressortir un portable sous Linux pour parvenir à le lancer.
La mise au point du script m’a pris pas mal de temps, mais une fois que j’ai compris la logique, j’ai avancé relativement vite : il suffisait en effet de repérer l’endroit de la page des résultats de recherche où figure la mention « Environ x résultats ».
Le plus compliqué à été de composer avec les sécurités qui se déclenchent sur les serveurs de Google quand on le sollicite trop : même en ralentissant beaucoup le rythme du robot passant sur ces pages, je finissais toujours par voir mon adresse IP bloquée.
2. Analyser les résultats dans Google Sheets
C’est en commençant à trier et à filtrer les résultats obtenus que je me suis aperçu qu’ils n’étaient pas toujours fiables : pour certains pays, les résultats trouvés dans Google Actualités (tous médias confondus) étaient en effet ajoutés au résultats trouvés sur un média particulier…
J’ai alors tenté ma chance sur Bing, mais ce dernier ne permet pas d’effectuer une recherche combinant plusieurs termes (avec l’opérateur OR) en ciblant un nom de domaine particulier.
De retour sur Google, j’ai fini par obtenir des données cohérentes en limitant la recherche aux pages publiées lors de l’année écoulée.
Il a fallu aussi traiter quelques cas particuliers – par exemple, le mot « Canada » apparaît sur toutes les pages du Huffington Post et de Buzzfeed, ces deux sites proposant un accès vers leur édition canadienne.
Il reste sans doute de petites aberrations de ce genre dans les données utilisées pour faire les cartes, mais j’ai considéré qu’elles n’étaient pas préjudiciables, vu la taille finale des cartes et leur niveau important de déformation.
3. Ajouter les résultats obtenus à une carte du monde grâce à QGIS
Le logiciel de cartographie avancé QGIS m’a permis d’ouvrir un shapefile (fichier de contours) trouvé sur ThematicMapping et de lui associer mes propres données via des recherches verticales dans la table.
Pour que ça marche, il faut une clé commune aux deux fichiers : en l’occurence, le code ISO à trois chiffres, que j’avais pris soin d’utiliser pour chaque pays étudié – je l’ajoute désormais systématiquement à toutes mes feuilles de calcul quand elles sont basées sur des pays, une précaution qui se révèle souvent utile.
4. Réaliser les anamorphoses avec ScapeToad
Disponible sur tous les OS via Java, ScapeToad est un petit logiciel plutôt bien fichu qui va réaliser la déformation du fichier shapefile en tenant compte, pour chaque pays, d’une valeur numérique disponible dans la table associée au fichier de contours.
Le résultat peut être enregistré au format d’image vectoriel SVG, ce qui permet de l’utiliser ensuite à n’importe quelle taille.
Attention : pour une carte du monde, les temps de calcul et de sauvegarde sont importants (surtout quand il faut recommencer la manipulation vingt fois pour vingt médias différents…).
5. Améliorer le résultat dans Adobe Illustrator
Le fichier SVG obtenu peut être facilement ouvert et modifié dans Illustrator, ce qui m’a permis de changer la couleur et la transparence des pays, et de créer une version PNG utilisée pour le partage Facebook.
Une fois les vingt cartes obtenues, j’ai créé la petite infographie permettant de basculer d’un média à l’autre en HTML, CSS et JQuery. Enfin, j’ai utilisé Datawrapper pour réaliser les deux graphiques également présents dans l’article.
A lire aussi
A propos
Dans mon labo, je publie mes expériences et je suis de près les révolutions que vivent les journalistes et les médias à l'ère du numérique.