Comme souvent, le travail que j’ai réalisé pour ma petite enquête sur la France de la VO et celle de la VF met en jeu toute une série d’outils que j’ai découvert au fil des ans, qu’il s’agisse de scraping, de jointures de tables ou de représentation par anamorphoses. L’ensemble des données dont je me suis servi est disponible dans une Google Sheet.
Je vais en décrire les différentes étapes, ce qui peut être utile si vous souhaitez vous lancer dans un chantier comparable. N’hésitez pas à mettre votre grain de sel dans les commentaires.
1. Récupérer la liste des séances avec un scraping en deux étapes avec Outwit Hub
Pour commencer, il fallu que je me constitue une base contenant l’ensemble des salles de cinéma de France. Par chance, le site Cinefil propose des pages listant tous les cinés d’un département (par exemple, ceux situés dans l’Ain).
J’ai d’abord généré automatiquement une URL pour chaque département sur cinefil.com dans Google Sheet. J’ai ouvert cette première liste dans Outwit Hub, un logiciel de scraping qui m’a permis de rassembler une liste de 1 409 salles. Pour chacune, j’ai aussi récupéré l’URL de sa page sur cinefil.com.
Sur ces 1 409 URL, j’ai fait passer un second scraper, afin de récupérer la liste des films diffusés dans chaque salle sur une journée, avec les horaires des séances et la version diffusée (VF ou VO). J’ai obtenu ainsi une liste de 14 423 films et de 20 182 séances.
2. Déterminer la langue de tournage dans chaque film avec OMDB
Après quelques heures de travail, je me suis aperçu d’une chose toute bête mais qui m’avait échappé : sur Cinefil, les séances des films en langue française sont indiquées « en VF », ce qui ne permet pas de les différencier automatiquement des films en langue étrangère diffusés en VF…
Il a donc fallu que j’établisse une liste des 982 films différents diffusés sur toute la France ce jour-là (le 28 avril), et que je trouve un moyen de déterminer, pour chacun d’entre eux, s’il s’agit à l’origine d’un film tourné en langue française ou en langue étrangère.
L’API Omdb m’a permis de récupérer cette information dans un bon nombre de cas, par l’intermédiaire de Cloud Ignite, un module complémentaire de Google Sheet particulièrement pratique.
Pour le reste, j’ai réalisé des croisements – par exemple, un film qui n’est diffusé qu’en VO sur toute la France ne peut être qu’un film en langue étrangère – et des déductions – par exemple, une coproduction France/Suisse/Belgique a de bonnes chances d’être tournée en français.
Ce tri s’est révélé fastidieux et le résultat n’est pas garanti sans erreurs, mais j’ai estimé sa fiabilité suffisante pour continuer à avancer, en mettant de côté tous les films en langue française.
3. Géolocaliser chaque salle de cinéma avec ezGecode
J’avais déjà récupéré l’adresse et le code postal de chaque cinéma sur sa page Cinefil. Pour en déduire sa latitude et sa longitude, j’ai utilisé un autre module complémentaire de Google Sheet, ezGeocode.
La grande majorité des salles a ainsi été géolocalisée automatiquement et avec une très bonne fiabilité, et j’ai réussi à placer le reste grâce à des recherches manuelles dans Google Maps.
4. Déterminer le code commune pour chaque salle de cinéma
Afin de « marier » la base que je me suis ainsi constituée avec les données démographiques fournies par l’Insee ou les résultats électoraux disponibles sur le site du ministère de l’Intérieur, il me fallait déterminer le code Insee de la commune où se trouve chacun des cinémas de ma liste.
J’ai pu le faire grâce à une table de correspondances et à la base officielle des codes postaux, toutes deux disponibles sur Data.gouv.fr. Une série de recherches verticales plus tard, j’avais pour chaque salle de cinéma des informations comme la population de la ville, le taux de pauvreté, le vote Macron…
Des tableaux croisés dynamiques m’ont ensuite permis de consolider les résultats pour chacune des 278 localités françaises pourvues d’au moins une salle de cinéma (avec au moins une séance programmée ce jour-là), puis pour chaque département.
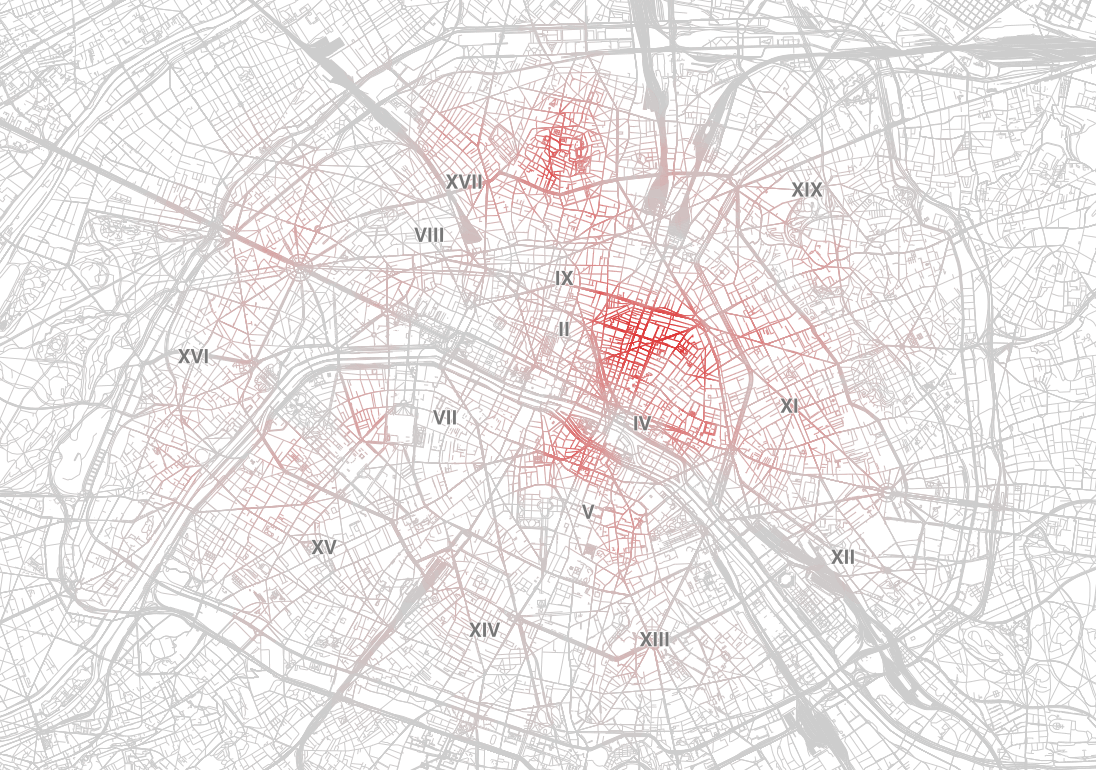
5. Réaliser les deux cartes interactives avec Carto
J’ai ensuite préparé deux séries de données, l’une avec toutes les salles où la part de la VO est majoritaire (#teamvo), et l’autre avec les salles plutôt VF (#teamvf).
J’ai créé deux cartes basées sur ces jeux dans Carto, et j’ai ajouté dans chacune d’elle un calque supplémentaire, avec les contours de chaque département et une couleur en fonction de la part de la VO ou de la VF à cette échelle.
J’ai passé pas mal de temps à chercher des réglages satisfaisants pour la taille des cercles, les nuances de couleurs ou encore la répartition des départements en cinq catégories (choix des intervalles).
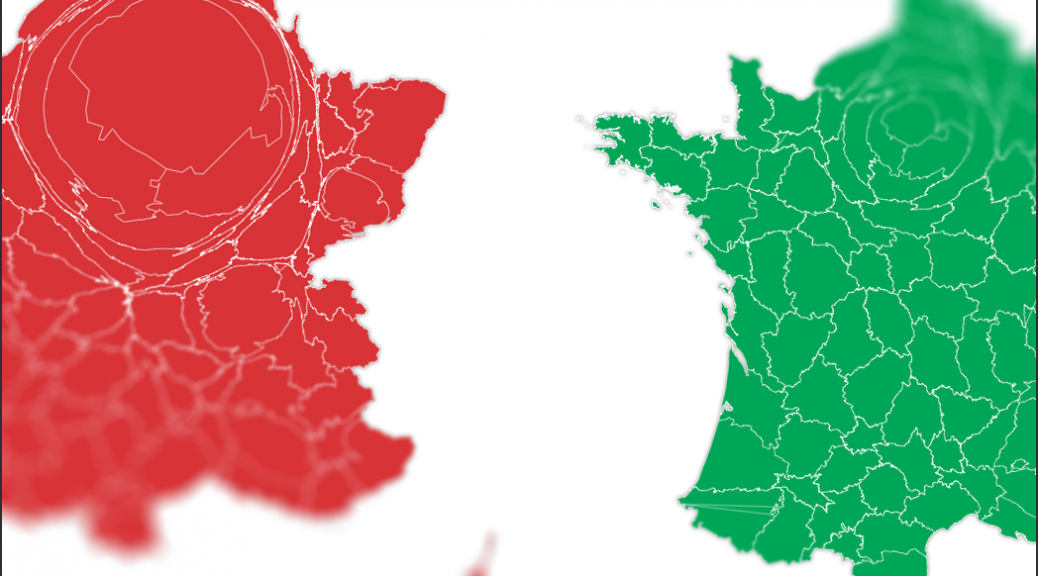
6. Réaliser les cartes anamorphosées avec Qgis et Scapetoad
J’avais déjà utilisé les anamorphoses (cartograms en anglais) pour une série de cartes du monde tel que le voient les médias français qui avait tapé dans l’œil de pas mal d’observateurs. J’avais envie de commencer mon article avec ce type de visiuels, que je trouve facile à appréhender même pour des lecteurs peu friands d’infographies.
J’ai récupéré un tracé des départements français au format shapefile sur OpenStreetMap.
J’ai ouvert ce fichier dans l’éditeur de cartes Qgis afin d’associer à chaque département le nombre de séances en VO et en VF pour un million d’habitants.
C’est sur la base de ces deux données que j’ai réalisé les déformations de la carte de France dans ScapeToad, un petit utilitaire dédié à la création d’anamorphoses.
7. Créer une série de graphiques dans Datawrapper
Pour terminer, j’ai repris une dernière fois mes données pour isoler une série de chiffres de synthèse afin de créer les graphiques de synthèses qui figurent à la fin de l’article, en reprenant les codes couleur.