Traquer les « cerise sur le gâteau », les « affaire à suivre » et les « grincer des dents » : c’était le thème de mon premier projet de datajournalisme. Dix ans plus tard, j’ai ressorti les pièges à loup du placard, et cherché à comprendre pourquoi les médias utilisaient autant ces expressions toutes faites.
Archives par mot-clé : data
Face à l’épidémie, ces graphiques qui ont (peut-être) sauvé des vies
Fin février, j’étais l’invité de Jean-Baptiste Diebold et de Philippe Couve pour leur podcast A Parte. Ces deux fins connaisseurs des médias en ligne m’ont soumis à un feu nourri de questions sur l’innovation dans les rédactions. L’une d’elles m’a un peu pris au dépourvu :
« On parle de ces questions de datajournalisme depuis une décennie, grosso modo, mais on a l’impression que ça reste toujours marginal… C’est quoi l’explication, c’est une allergie au tableur Excel de la part des journalistes, ou bien les données, c’est compliqué à utiliser, c’est pas si exploitable que ça ? »
Sur le moment, j’ai bredouillé ma réponse habituelle : le datajournalisme n’est plus vraiment à la mode, certes, mais c’est plutôt une bonne nouvelle ; ça permet à ces nouvelles pratiques de s’implanter lentement mais durablement dans les esprits. Et puis les initiatives se multiplient, on voit se multiplier les projets vraiment aboutis, la connaissance des outils, y compris les plus pointus, se répand.
La bulle confortable de la formation, et le monde réel
Mais j’avais toujours un doute. Quand j’anime des formations sur ce thème, il y a toujours un moment où les participants se découragent devant la technicité de la discipline et les pièges variés qu’ils vont devoir affronter. Le datajournalisme est, par essence, un journalisme de la complexité. Même une série de données d’apparence simple, téléchargée sur un site officiel et correctement structurée, peut plonger dans des abîmes de perplexité.
Prenez le produit intérieur brut, par exemple. Faut-il privilégier le PIB global, celui par habitant, celui « à parité de pouvoir d’achat » ? Pourquoi les montants sont-ils différents selon la Banque mondiale, l’OCDE et Eurostat ? Et que faire quand des cases du tableau sont désespérément vides ?
Il y a la bulle confortable de la formation, dans laquelle on prend le temps de se poser toutes ces questions. Et puis il y a le monde réel, les conditions de travail dégradées des journalistes, les plans d’économie qui se multiplient, la perte d’expertise au sein des équipes, la course au clic et l’abus du copié-collé, la prime à la publication « en temps réel »…
Dans ce contexte, il faut être du genre utopiste pour penser que la profession finisse par accorder assez d’attention, de temps et d’énergie à la maîtrise de ces nouveaux outils.
Le miroir de notre angoisse collective
Et puis l’épidémie de Covid-19 est arrivée, et elle a balayé mes doutes. Dès les premiers jours, les chiffres, les tableaux, les graphiques ont poussé comme des champignons après la pluie. Les courbes exponentielles de l’université Johns Hopkins, dont les chiffres sont repris un peu partout, sont devenues le miroir de notre angoisse collective.

Avec d’autres, elles ont permis une prise de conscience mondiale. Elles sont donné de la résonance aux récits des habitants de Hubei, des médecins de Bergame, du personnel des Ehpad du Haut-Rhin, des confinés fliqués à Séoul, des nouveaux chômeurs de New York.
Il a fallu de sinistres asymptotes pour connecter toutes ces histoires individuelles, en faire une expérience collective, la rendre réelle, palpable, mesurable. Au passage, ces graphiques ont, sans doute, sauvé pas mal de vies.
Impossible d’en faire un inventaire complet. Du tableau de bord multi-critères, des cartes interactives, des graphiques dignes de publications scientifiques ou bien dessinés sur un coin de table… : tous les formats y sont passés.
On trouvera des compilations plus complètes dans les newsletters de Datagif (français), de Giuseppe Sollazo (anglais) ou de J++ Stockhom (anglais). (Ça ne veut pas dire que tout ce qui a été publié était de qualité, on trouvera d’ailleurs une série d’exemples à‑ne-pas-reproduire-chez-vous dans ce post Medium de l’infographiste Amanda Makulec.)
Des graphiques remixés comme de vulgaires mèmes
Mais certains m’ont particulièrement marqués. Ou plutôt, ce qui m’a frappé, c’est de les voir partagés, commentés, détournés, remixés par la culture populaire comme de vulgaires mèmes.
Le graphique « Flatten the curve », est apparu, selon le site Know Your Meme, le 28 février. Depuis, il a été dupliqué et décliné à l’infini, parce qu’il se révélait un outil redoutable pour faire comprendre l’intérêt des mesures de distanciation sociale, dans une forme que même le plus buté des présentateurs de Fox News pouvait comprendre.
Important to remember that #Covid-19 epidemic control measures may only delay cases, not prevent. However, this helps limit surge and gives hospitals time to prepare and manage. It’s the difference between finding an ICU bed & ventilator or being treated in the parking lot tent. pic.twitter.com/VOyfBcLMus
— Drew A. Harris, DPM, MPH (@drewaharris) February 28, 2020
Il est difficile d’en connaître l’impact exact dans la population – le monde réel ne se résume pas aux réseaux sociaux, ou plutôt à la bulle qu’ils créent autour de chacun de nous. Mais il est permis de penser que deux bosses et un trait vertical auront fait davantage pour faire passer un message de santé publique que bien des déclarations officielles.
Les politiques, d’ailleurs, ont rapidement compris que leurs propos avaient plus de chances de convaincre s’ils s’appuyaient sur des visuels. Ainsi, Olivier Véran dessinant le « Flatten the curve » en direct sur BFM-TV.
« L’objectif est de retarder le pic épidémique et de baisser le volume de malades«
— BFMTV (@BFMTV) March 9, 2020
Le schéma du ministre de la Santé pour expliquer la stratégie du gouvernement contre le coronavirus ⤵ pic.twitter.com/PmZDaYmMwg
« C’est trop compliqué pour le lecteur » Vraiment ?
Publié le 10 mars, le post Medium de Tomas Pueyo, titré « Coronavirus : Why You Must Act Now » se situe aussi dans le registre de la sensibilisation. Mais en termes de format, c’est l’extrême opposé : un long raisonnement, de multiples graphiques parfois complexes, l’accent mis sur les biais et les erreurs d’interprétation.

Tout ce qu’il ne faut pas faire quand on veut attirer l’attention du grand public sur les supports numériques, vous diront les spécialistes. Sauf que la version anglaise a été vue plusieurs millions de fois, et le texte a été traduit dans plus de trente langues…
Un succès qui relance la question de la capacité réelle des lecteurs à s’approprier les cartes, les graphiques, les schémas, les tableaux… En anglais, on parle de graphicacy, sur le modèle de la literacy, le fait de savoir lire et écrire un texte. « C’est trop compliqué pour le lecteur » est un argument souvent avancé dans les rédactions contre l’utilisation de la datavisualisation, surtout si on s’aventure hors des formats les plus simples (barres et courbes).
A minima, on dirait bien qu’on a sous-estimé les lecteurs. Après tout, selon l’OCDE, un tiers de la population française est diplômée du supérieur (45% pour les 25–34 ans) et a dû croiser pas mal d’abscisses et d’ordonnées pendant sa scolarité. Quand aux autres, il n’est pas interdit de penser qu’en soignant la présentation et l’interprétation, il seront aussi capables de s’approprier ce type de présentation de l’information.
Une échelle logarithmique et des courbes qui s’empilent
Ce n’est pas la seule certitude que cette pandémie bouscule dans le domaine de la visualisation – sur ce sujet, Rosamund Pierce, infographiste à The Economist, dressait récemment la liste des règles qu’il faut savoir ne pas respecter, parfois.
Au début de l’épidémie, les graphiques du Financial Times, que John Burn-Murdoch présente dans une vidéo très éclairante, tordaient ainsi le cou à quelques dogmes pourtant bien établis :
- une échelle logarithmique, supposée déroutante et réservée aux publications scientifiques, mais qui est un choix finalement bien naturel pour parler d’un phénomène exponentiel ;
- un empilement de courbes et de couleurs qu’on pourrait juger peu lisible, mais qui permet en un coup d’œil de différencier les pays « qui s’en sortent » de ceux qui peinent à endiguer la propagation de la maladie ;
- des guides en pointillés qui surchargent encore l’affichage, mais sont indispensables pour mieux estimer le rythme de propagation, alors que la pandémie en était encore à ses débuts dans beaucoup de régions.
And cases in cumulative form :
— John Burn-Murdoch (@jburnmurdoch) April 3, 2020
• US very much in uncharted territory. Now accounts for 1‑in‑4 confirmed cases worldwide
• India perhaps stabilising again. Shows the importance of watching medium-term trends, not short term bumps which could be due to data backlogs pic.twitter.com/T9YCSMplfG
Aussi sophistiqués soient-ils, leur lecture reste aisée, et leur publication quotidienne comme les commentaires qui les accompagnent sont vite devenus un rendez-vous incontournable, au moins pour les confinés de ma timeline Twitter.
Tout choix éditorial est un pari, et parfois les paris se gagnent
Quid des projets plus ambitieux ? En matière de datavisualisation, les productions léchées des grosses équipes du New York Times, de Reuters ou du National Geographic font peur à certains rédacteurs en chef. Trop chronophage, trop ambitieux, trop incertain. (L’an dernier, j’ai ressenti un pincement dans mon cœur de patriote en voyant que c’est un média américain, et non français, qui a publié le format le plus convaincant sur l’incendie de Notre-Dame.)
Oui, mais voilà : tout choix éditorial est un pari, et, parfois, les paris se gagnent. Le simulateur d’épidémie publié par le Washington Post est désormais le contenu le plus visité de toute l’histoire de ce média, et a marqué beaucoup de ses lecteurs. Certes, on n’arrive pas à un tel niveau de qualité sans en passer par des années d’apprentissage, de montée en compétence de l’équipe, de recrutements avisés. Par des essais, d’erreurs et des résultats décevants. Mais qui osera dire aujourd’hui que ça n’en vaut pas la peine ?
Alberto Cairo, consultant renommé et auteur de « How Charts Lie”, résume mon sentiment sur son blog :
« C’est quelque chose qui m’intrigue : pourquoi autant d’entreprises – et je ne parle pas seulement des médias – sont aussi réticentes à investir dans des équipes data et infographies, ou bien à leur donner assez de ressources et d’autonomie pour les développer ? »
Pour se consoler, les médias qui ont raté le train peuvent se dire qu’ils ne sont pas les seuls à manquer aujourd’hui de ressources. J’ai été frappé de voir circuler l’appel aux volontaires non-soignants lancé il y a dix jours par Assistance Publique – Hôpitaux de Paris (AP-HP). Plus de 13 000 personnes ont depuis rejoint le Slack dédié, dont 600 ont rejoint l’une des 36 missions proposées, selon le communiqué publié le 1er avril.
Parmi les profils recherchés initialement : des data-scientists, des développeurs, des chefs de projet, des designers, des spécialistes UX… Autant de métiers encore mal identifiés, associés à la geste macronienne de la start-up nation, et dont il est de bon ton de se gausser quand on est humoriste sur France inter.
Evidemment, toutes ces bonnes volontés ne remplaceront jamais un système hospitalier correctement financé et des soignants en nombre suffisant. Mais leurs compétences se révèlent utiles pour une bataille qui se joue aussi sur le front de la data, et pas seulement dans les rédactions.
(Merci à Karen Bastien et Alexandre Léchenet pour leurs conseils.)

Les prix fous du train : ville par ville, les tarifs relevés sur le site de la SNCF
Pour connaître le prix de son billet de train, il a longtemps suffi de faire une simple multiplication : le nombre de kilomètres à parcourir par le prix du kilomètre. Ce principe de péréquation a duré de la création de la SNCF, en 1938, jusqu’en 1970, quand la compagnie a commencé à moduler les tarifs du train en fonction d’autres critères.
Cette époque semble bien lointaine à l’heure du yield management, un principe de tarification généralisé par la SNCF à partir de 1993, qui permet d’optimiser les revenus, en s’assurant qu’un maximum de sièges sont occupés, et que leurs occupants ont payé la somme maximale qu’il étaient prêt à consacrer à cette dépense.
Résultat : pour beaucoup d’usagers du train, la valse des étiquettes peut sembler folle, tant ils varient d’un train sur l’autre et d’un jour à l’autre – sauf sur certaines liaisons, en vertu d’accords entre la SNCF et les régions.
L’offre et la demande font leur loi, et les prix s’envolent si la seconde dépasse la première, comme cet automne, quand la compagnie a ouvert à la vente les billets des vacances de Noël, jugés trop chers et trop rares par beaucoup d’usagers.
11 000 tarifs relevés pour une trentaine de villes, en suivant divers scénarios
Mais dans quel mesure évoluent ces prix ? Quels plafonds et quels planchers peuvent-ils atteindre ? Pour répondre, j’ai relevé automatiquement plus de 11 000 tarifs proposés sur le site Oui.sncf pour des trajets entre Paris et une trentaine de villes de France, en fonction de divers scénarios.
J’ai ainsi simulé un voyage prévu la veille pour le lendemain, un week-end prévu longtemps à l’avance, un déplacement dans le creux de la semaine d’autres en période de pointe, comme à la Toussaint ou à Noël. Les résultats montrent des variations de tarifs très fortes.
Selon le chercheur Jean Finez, auteur d’une intéressante « socio-histoire » de la tarification SNCF, le prix pour parcourir 100 kilomètres en deuxième classe était de 84 F en 1944, hors tarifs sociaux (les familles nombreuses, les militaires…) ou opérations commerciales. Soit, si on tient compte de l’inflation, 20 € de 2018. Par exemple, un Paris-Lyon (510 kilomètres de voie ferrée) devait alors coûter 428 F, soit 100 € de 2018.
Mes relevés semblent montrer que ce prix est un peu moins élevé aujourd’hui, avec une moyenne globale de 18,60 € pour 100 kilomètres. Le Paris-Lyon revient en moyenne à 83,80 €.
Cette moyenne cache de fortes variations : un Paris-Marseille peut passer de 16 € à 212 €. Cet exemple est un peu trompeur cependant : le tarif maximum correspond à un billet de première classe, la seconde classe étant complète. C’est ce que m’indiquait l’économiste Thomas Le Gouezigou sur Twitter peu de temps après la parution de cet article. Le plafond prévu par la loi pour la seconde classe, rappelle-t-il, est de 116 €.
En tout cas, toutes les villes ne sont pas logées à la même enseigne : un Rémois vivant à Paris et souhaitant rentrer chez lui se voit proposer un prix moyen de 28,50 € pour 100 kilomètres, contre 14,40 € les 100 km pour son compatriote toulonnais.
Le prix au kilomètre parcouru varie fortement selon les destinations
Est-ce un effet de la concurrence de l’avion sur les longues distances ? Mes pointages montrent que le prix au kilomètre diminue en fonction de la distance parcourue. C’est notamment le cas au bout de la LGV Sud-Est : les Niçois, les Marseillais ou les Perpignanais paient moins cher leur voyage, du moins selon ce critère.
Le prix au kilomètre diminue avec le nombre de kilomètres parcourus
En revanche, il ne semble pas y avoir de lien entre le prix au kilomètre affiché et la richesse des villes desservies (estimée ici avec la médiane du niveau de vie que calcule l’Insee pour chaque commune).
Le prix au kilomètre ne varie pas avec la richesse des villes desservies
Mais voyager dans une vieille voiture de deuxième classe tracté par une poussive micheline, ce n’est pas tout à fait la même chose que de filer plus vite que le vent dans un TGV dernier cri. Pour le fun, j’ai donc aussi calculé un prix au kilomètre/heure (en me basant sur les heures de départ et d’arrivée ainsi que la distance à vol d’oiseau entre les deux villes), et établi un autre classement selon ce critère.
Le prix au km/h est aussi très variable
Si le sujet vous intéresse et que vous souhaitez faire d’autres comparaisons, mes données sont disponibles sous forme de Google Sheet. Les curieux liront aussi ce billet d’Arthur Charpentier sur le site Freakonometrics.
Mise à jour le 17 décembre à 00h30. Sur Twitter, l’économiste Thomas Le Gouezigou fait remarquer que lorsque la seconde classe est complète, le site Oui.sncf propose les places restantes en première classe. J’ai ajouté un passage et corrigé les textes des infographies en conséquence.
Photo en page d’accueil : deux TGV en gare (TGr_79 / Flickr / CC-BY-SA)
Ce qui a changé dans la liste des sujets préférés des médias français
Vous avez été nombreux à montrer votre intérêt pour le tableau de bord des obsessions, marottes et zones d’ombre des médias que j’ai publié début février. Je vais donc continuer de le compléter et de l’améliorer dès que j’aurais un peu de temps devant moi, et listé dans ce post les derniers changements.
Vendredi 5 octobre
Après une série de tests, affichage des graphiques montrant l’évolution du traitement d’un thème depuis un mois.
Lundi 6 août
La mise à jour des informations ne se faisait plus, la faute à un problème sur le flux RSS d’un des médias. Problème désormais réparé.
Samedi 10 février
- Une dizaine de médias supplémentaires sont désormais étudiés : Courrier international, L’Equipe, Les Echos, La Tribune, Challenges, Capital, Reporterre, L’imprévu, Bastamag, Contexte, StreetPress, The Conversation.
- Dans la liste des entités, le classement actuel et son évolution par rapport à la période précédente est indiqué, à la manière du Top 50.
- Le script qui récupère les titres et descriptions des articles publiés par chaque média (via leur flux RSS) passe désormais une fois par heure, et non plus trois fois par jour, pour ne rien rater sur les sites qui publient beaucoup de contenu comme 20 minutes.
- L’adresse du flux RSS utilisé pour L’Express était erronée et a été corrigée.
- La qualité du corpus utilisé pour l’analyse a été beaucoup améliorée : problèmes d’encodage résolus (Le Monde, Vice…), balises HTML mieux filtrées (Mashable…), suppression des retours chariots, retours à la ligne et tabulations.
- Le corpus ne contient plus que les 150 premiers caractères de la description de chaque article publié, afin de ne pas défavoriser dans l’analyse les sites qui ne fournissent qu’une description très courte dans leur fil RSS, comme Le Point.
- Trois médias ne peuvent être étudiés : Buzzfeed (contenus en anglais dans le fil RSS), Valeurs actuelles (fil RSS illisible), Télérama (pas de fil RSS disponible).
Comment je prépare le tableau de bord des sujets les plus traités par les sites d’actu
C’est sans doute le projet le plus ambitieux et le plus complexe que j’aie mené à bien depuis que j’ai lancé Dans mon labo il y a bientôt quatre ans. Il m’a fallu pas mal d’après-midi pluvieux et de jours fériés blafards pour terminer le tableau de bord qui liste les sujets les plus présents dans les sites d’actualité français.
Il est devenu possible grâce aux progrès que j’ai réalisés en Python, un langage de programmation prisé des datajournalistes. De mon côté, j’ai dû sérieusement m’y mettre courant 2017, notamment pour afficher en direct les résultats des élections législatives au sein de la carte interactive que j’ai préparée pour Contexte.
Pour explorer les flux XML mis à disposition par le ministère de l’Intérieur le soir des scrutins, j’ai trouvé en Python, avec sa syntaxe accessible et ses multiplies librairies disponibles, un partenaire idéal. (Mais il est aussi possible de faire ça très bien avec d’autres solutions, comme R.)
Et ces connaissances m’ont ouvert de nouveaux horizons, notamment ceux de la reconnaissance automatisée d’entités nommées. Un domaine qui, m’a-t-on expliqué, a beaucoup progressé grâce au patient travail de description et de classement réalisé par les contributeurs de Wikipedia.
J’ai d’abord travaillé, toujours pour Contexte, sur les thématiques les plus présentes dans le discours des députés pour enrichir le trombinoscope de l’Assemblée nationale que le site propose à ses abonnés. C’est alors que m’est venue l’idée de proposer une démarche comparable, mais avec les médias en ligne.
1. Scraper les flux RSS des sites d‘actu avec Python
J’ai listé, dans une Google Sheet, les sites que je souhaitais étudier, en renseignant pour chacun l’adresse de son flux RSS principal.
Mon script de scraping (dispo pour les curieux) commence par récupérer cette liste, et va chercher dans chaque flux le titre et la description (le chapô ou le début du texte) de chaque article. Il récupère aussi sa date de publication, et enregistre le tout dans un fichier Json dédié à chaque site.
Tous les flux RSS n’étant pas construits de la même façon, il a fallu prendre en compte les différents cas de figure : ainsi, le résumé de l’article se trouve dans un élément qui peut être nommé « description », « summary », « content »…
2. Créer un corpus de textes et le faire analyser par TextRazor
La suite de ce script va concaténer ensemble les titres et résumés de chaque article publiés dans une période donnée pour en faire un seul et même texte.
Ce corpus va ensuite être envoyé à TextRazor, via la librairie Python que met à disposition ce service d’analyse sémantique. Ce dernier est gratuit jusqu’à 500 requêtes par jour, un quota largement suffisant pour ce projet.
Parmi les services équivalents, TextRazor a un autre avantage : non seulement son outil d’extraction des entités nommées renvoie la liste des thématiques détectées au sein du corpus soumis, mais il fournit aussi pour chacune un score de relevance (« pertinence », que j’ai finalement traduit en « présence » dans mon tableau de bord).
Ainsi, s’il détecte les mots « GPA », « gestation pour autrui » ou « mère porteuse » dans un texte, Textrazor réunit ses expressions dans une seule thématique (en général le titre de la notice Wikipedia dédiée). Et donne à cette dernière une note, de 0 à 1, selon que l’entité lui semble plus ou moins pertinente dans le texte fourni.
C’est à la fois la force et la faiblesse de ma méthode : ce scoring me permet de générer les multiples classements, mais je n’ai pas « la main » sur son élaboration.
Malgré quelques mauvaises surprises, l’observation des résultats obtenus m’a toute fois rassuré : Le Parisien est en général le média où le thème « Paris » est le plus présent ; on retrouve souvent « Jean-Luc Mélenchon » bien classé dans les résultats de Politis ; Sputnik et RT France sont bien placés au classement pour le thème « Vladimir Poutine ».
4. Héberger les scripts sur un serveur chez PythonAnywhere
Cette partie-là du chantier serait une promenade de santé pour un développeur back-end même débutant. A un journaliste bidouilleur comme moi, elle a pris pas mal de temps et d’énergie.
Une fois le script Python décrit ci-dessus terminé, je ne pouvais pas l’exécuter moi-même plusieurs fois par jour sur mon ordinateur afin de disposer de données toujours fraîches pour alimenter un éventuel tableau de bord.
Sur les conseils d’amis développeurs, j’ai regardé plusieurs offres d’hébergement comme Amazon Web Services ou Google Cloud Platform, mais la longueur des procédures d’installation et des tutoriels proposés m’a vite refroidi. Je me suis rabattu sur Python Anywhere. un service peu onéreux et qui s’est révélé mieux adapté à un noob comme moi.
Même avec cette solution, je suis passé par mal, de guides d’utilisation, de pages d’aide et de questions Stack Overflow avant d’arriver mes fins : faire tourner mon script de scraping plusieurs fois par jour.
4. Créer le tableau de bord en front à partir d’un fichier Json optimisé
Une fois toutes ces listes de thématiques récupérées et enregistrées dans le fichier Json de chaque média, un autre script Python, lui aussi hébergé sur PythonAnywhere, va préparer un fichier Json commun et de taille réduite.
Ce dernier sera récupéré, au moment où le tableau de bord publié Dans mon labo se charge, par votre navigateur. Au final, c’est donc Chrome, Firefox ou Edge qui va construire l’infographie à l’intérieur de la page.
Je ne détaillerais pas sur ce travail de développement front-end, classique combinaison de HTML, de CSS et de Javascript, mais si vous avez des questions sur cette partie, je serai ravi d’y répondre !
A ce stade, la principale difficulté pour moi a été de s’assurer que le chargement des données puis la construction de l’infographie se fasse dans un délai raisonnable : lors des premières étapes, le tout prenait parfois une bonne dizaine de secondes, ce qui es rédhibitoire.
Pour chaque média, j’ai choisi de ne pas intégrer une thématique si son score était inférieur à un certain seuil (en ce moment, 0,4/1), et de n’afficher une thématique dans la liste principale que si elle était présente dans au moins quatre médias.
Il m’a fallu pas mal d’allers-retours entre scripts Python sur le serveur et code Javascript dans le navigateur pour réduire ce délai et obtenir une expérience suffisamment fluide, mais il reste sans doute pas mal d’optimisation possible.
5. Préparer la suite avec des analyses hebdomadaires et mensuelles
Comme beaucoup l’ont fait remarquer dès la publication du tableau de bord, les résultats seront intéressants à observer dans le temps, au-delà de la photographie actuelle (les sept derniers jours). Mon script réalise déjà des analyses hebdomadaires et mensuelles, qui ne sont pas affichées mais que j’espère utiliser quand j’aurais davantage de recul. (Edit le 5 octobre : des graphiques s’affichent désormais pour chaque thématique, j’y reviens dans un thread sur Twitter)
Voilà ! Je suis en tout cas curieux de savoir vos remarques, critiques ou propositions d’amélioration dans les commentaires de ce post ou bien, pour les timides, dans un message privé.
Mis à jour le 2/2 à 10h15. Précision sur les seuils (point 4) et point 5 ajouté.
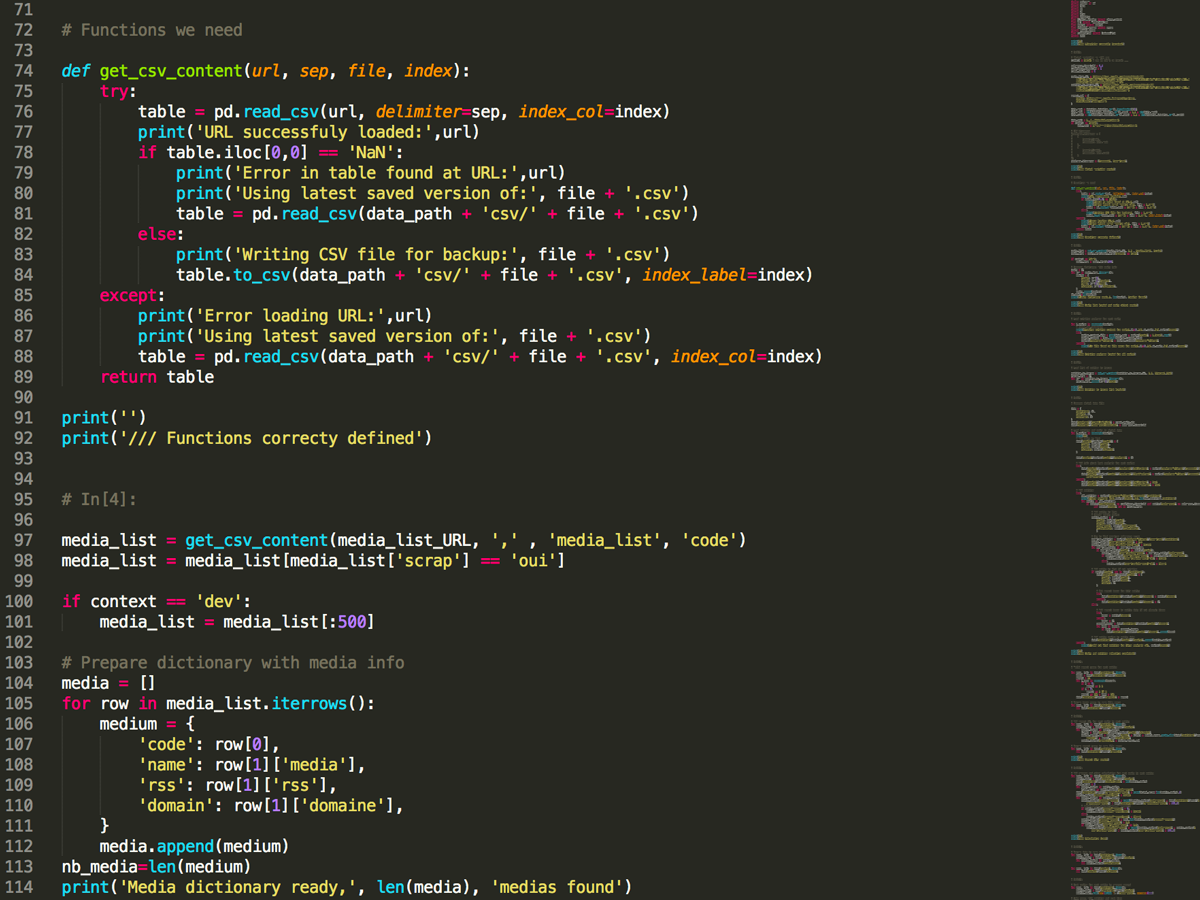
Obsessions, marottes et zones d’ombre : voici les sujets préférés de 60 sites d’info français
Dans une rédaction, la ligne éditoriale, c’est comme le dahu : tout le monde en parle, mais personne ne l’a jamais vue. Elle structure pourtant le travail quotidien des journalistes ; c’est en son nom qu’on va accepter ou refuser une idée de sujet ou d’angle. Et quand elle est absente ou bien trop floue, ce n’est souvent pas bon signe.
Pour tenter de représenter ces fameuses lignes, j’ai mis au point ce tableau de bord, qui montre les thématiques les plus présentes sur une soixantaine de sites d’actualité dans les sept derniers jours, le tout rafraîchi trois fois par jour.
Encore expérimentales, ces listes sont générées automatiquement, grâce à la reconnaissance d’entités nommées dans un corpus spécifique à chaque média. Cet agglomérat de texte est formé avec les informations disponibles au sein de son flux RSS principal – je reviens en détail sur la méthodologie utilisée dans un autre post.
Mis à jour le 5/10/2018. L’infographie a pas mal évolué depuis sa publication, voir la liste des changements dans ce post.
Mis à jour le 15/11/2019. Le tableau de bord n’est plus mis à jour.

Bataille de bouffe ! Découvrez les ingrédients et recettes préférés des Français
Mettez deux Français ensemble, et il y a de bonnes chances qu’après quelques minutes, ils se mettent à parler de bouffe, qu’il s’agisse du dernier restaurant à la mode ou de cette recette exclusive de moelleux au chocolat qu’ils sortent du tiroir pour les grandes occasions.
Mais quels sont les aliments et les préparations préférés des Français ? Pour le savoir, j’ai « aspiré » les données d’un des sites de recettes les plus populaires, Marmiton, Vous pouvez découvrir les résultats en lançant des batailles d’ingrédients dans l’infographie ci-dessous.
Pour calculer le score d’un ingrédient, j’ai d’abord récupéré toutes les recettes qui le contiennent, grâce à un script en Python. Ensuite j’ai multiplié, pour chacune de ces dernières, le nombre d’avis d’internautes par la note moyenne obtenue. Et j’ai additionné le tout.
Je n’ai gardé que les 1 130 ingrédients qui apparaissent dans au moins 10 recettes, et opéré pas mal de regroupements pour obtenir des résultats plus pertinents (par exemple, « échine de porc », « côtes de porc » ou « escalope de porc » sont toutes regroupées dans l’ingrédient « porc »). La liste retenue contient finalement 871 entrées, de A comme « abricot » à Y comme « yaourt ».
Il m’a aussi fallu créer une cinquantaine de catégories (de « viandes » à « produits laitiers » en passant par « bonbons » ou « champignons ») afin de générer les classements. N’hésitez pas à me signaler des erreurs ou des bizarreries dans les commentaires ou en me contactant, afin que je les corrige.
Vous pouvez aussi consulter les données sur les ingrédients comme celles sur les catégories, pour les réutiliser si vous le souhaitez.
Comment j’ai réalisé les cartes de France de la VO et de la VF
Comme souvent, le travail que j’ai réalisé pour ma petite enquête sur la France de la VO et celle de la VF met en jeu toute une série d’outils que j’ai découvert au fil des ans, qu’il s’agisse de scraping, de jointures de tables ou de représentation par anamorphoses. L’ensemble des données dont je me suis servi est disponible dans une Google Sheet.
Je vais en décrire les différentes étapes, ce qui peut être utile si vous souhaitez vous lancer dans un chantier comparable. N’hésitez pas à mettre votre grain de sel dans les commentaires.
1. Récupérer la liste des séances avec un scraping en deux étapes avec Outwit Hub
Pour commencer, il fallu que je me constitue une base contenant l’ensemble des salles de cinéma de France. Par chance, le site Cinefil propose des pages listant tous les cinés d’un département (par exemple, ceux situés dans l’Ain).
J’ai d’abord généré automatiquement une URL pour chaque département sur cinefil.com dans Google Sheet. J’ai ouvert cette première liste dans Outwit Hub, un logiciel de scraping qui m’a permis de rassembler une liste de 1 409 salles. Pour chacune, j’ai aussi récupéré l’URL de sa page sur cinefil.com.
Sur ces 1 409 URL, j’ai fait passer un second scraper, afin de récupérer la liste des films diffusés dans chaque salle sur une journée, avec les horaires des séances et la version diffusée (VF ou VO). J’ai obtenu ainsi une liste de 14 423 films et de 20 182 séances.
2. Déterminer la langue de tournage dans chaque film avec OMDB
Après quelques heures de travail, je me suis aperçu d’une chose toute bête mais qui m’avait échappé : sur Cinefil, les séances des films en langue française sont indiquées « en VF », ce qui ne permet pas de les différencier automatiquement des films en langue étrangère diffusés en VF…
Il a donc fallu que j’établisse une liste des 982 films différents diffusés sur toute la France ce jour-là (le 28 avril), et que je trouve un moyen de déterminer, pour chacun d’entre eux, s’il s’agit à l’origine d’un film tourné en langue française ou en langue étrangère.
L’API Omdb m’a permis de récupérer cette information dans un bon nombre de cas, par l’intermédiaire de Cloud Ignite, un module complémentaire de Google Sheet particulièrement pratique.
Pour le reste, j’ai réalisé des croisements – par exemple, un film qui n’est diffusé qu’en VO sur toute la France ne peut être qu’un film en langue étrangère – et des déductions – par exemple, une coproduction France/Suisse/Belgique a de bonnes chances d’être tournée en français.
Ce tri s’est révélé fastidieux et le résultat n’est pas garanti sans erreurs, mais j’ai estimé sa fiabilité suffisante pour continuer à avancer, en mettant de côté tous les films en langue française.
3. Géolocaliser chaque salle de cinéma avec ezGecode
J’avais déjà récupéré l’adresse et le code postal de chaque cinéma sur sa page Cinefil. Pour en déduire sa latitude et sa longitude, j’ai utilisé un autre module complémentaire de Google Sheet, ezGeocode.
La grande majorité des salles a ainsi été géolocalisée automatiquement et avec une très bonne fiabilité, et j’ai réussi à placer le reste grâce à des recherches manuelles dans Google Maps.
4. Déterminer le code commune pour chaque salle de cinéma
Afin de « marier » la base que je me suis ainsi constituée avec les données démographiques fournies par l’Insee ou les résultats électoraux disponibles sur le site du ministère de l’Intérieur, il me fallait déterminer le code Insee de la commune où se trouve chacun des cinémas de ma liste.
J’ai pu le faire grâce à une table de correspondances et à la base officielle des codes postaux, toutes deux disponibles sur Data.gouv.fr. Une série de recherches verticales plus tard, j’avais pour chaque salle de cinéma des informations comme la population de la ville, le taux de pauvreté, le vote Macron…
Des tableaux croisés dynamiques m’ont ensuite permis de consolider les résultats pour chacune des 278 localités françaises pourvues d’au moins une salle de cinéma (avec au moins une séance programmée ce jour-là), puis pour chaque département.
5. Réaliser les deux cartes interactives avec Carto
J’ai ensuite préparé deux séries de données, l’une avec toutes les salles où la part de la VO est majoritaire (#teamvo), et l’autre avec les salles plutôt VF (#teamvf).
J’ai créé deux cartes basées sur ces jeux dans Carto, et j’ai ajouté dans chacune d’elle un calque supplémentaire, avec les contours de chaque département et une couleur en fonction de la part de la VO ou de la VF à cette échelle.
J’ai passé pas mal de temps à chercher des réglages satisfaisants pour la taille des cercles, les nuances de couleurs ou encore la répartition des départements en cinq catégories (choix des intervalles).
6. Réaliser les cartes anamorphosées avec Qgis et Scapetoad
J’avais déjà utilisé les anamorphoses (cartograms en anglais) pour une série de cartes du monde tel que le voient les médias français qui avait tapé dans l’œil de pas mal d’observateurs. J’avais envie de commencer mon article avec ce type de visiuels, que je trouve facile à appréhender même pour des lecteurs peu friands d’infographies.
J’ai récupéré un tracé des départements français au format shapefile sur OpenStreetMap.
J’ai ouvert ce fichier dans l’éditeur de cartes Qgis afin d’associer à chaque département le nombre de séances en VO et en VF pour un million d’habitants.
C’est sur la base de ces deux données que j’ai réalisé les déformations de la carte de France dans ScapeToad, un petit utilitaire dédié à la création d’anamorphoses.
7. Créer une série de graphiques dans Datawrapper
Pour terminer, j’ai repris une dernière fois mes données pour isoler une série de chiffres de synthèse afin de créer les graphiques de synthèses qui figurent à la fin de l’article, en reprenant les codes couleur.
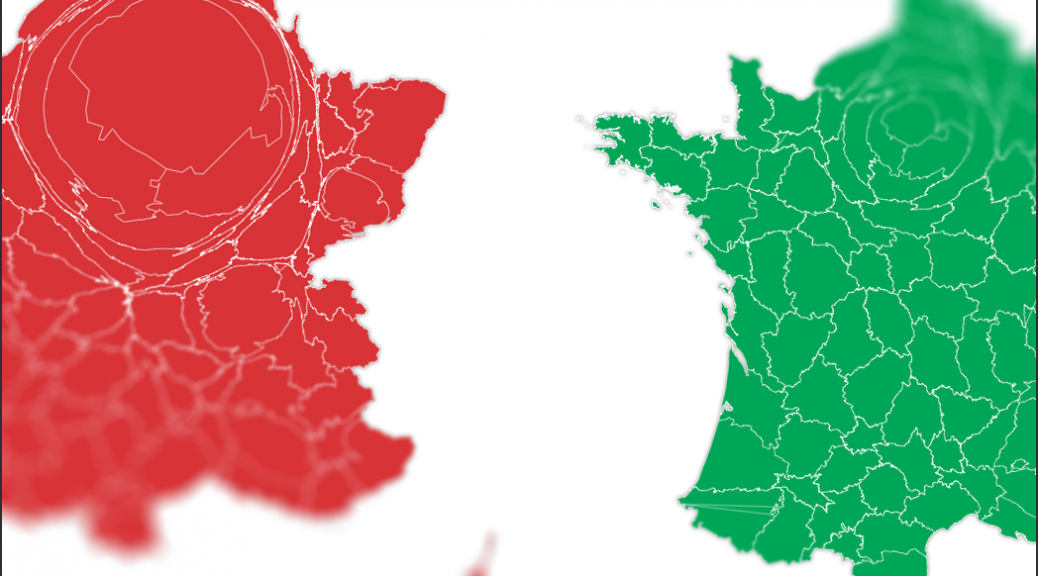
La France de la VO et celle de la VF : les cartes d’une fracture française

La France de la VO

La France de la VF
Ça fait partie de ces combats qui divisent les Français en deux camps irréconciliables. Comme la guerre sans merci du « pain au chocolat » et de la « chocolatine », ou le conflit séculaire entre la tartine au beurre salé et celle au beurre doux.
De même, il y a ceux qui ne jurent que par la version originale sous-titrée (VO) – quitte à passer son temps à lire les sous-titres plutôt qu’à profiter de l’action et des dialogues – et ceux qui ne peuvent pas vivre sans la version française (VF) – quitte à subir des traductions et des doublages pas toujours parfaits.
Histoire de frustrer un peu tout le monde, les cinémas ne proposent pas forcément les deux versions. Sur les deux anamorphoses en haut de cet article, plus un département est gros et plus ses habitants se voient proposer de séances en VO (à gauche, en rouge) ou de la VF (à droite, en vert).
Sur une journée, 20 182 séances de cinéma dans 1 400 salles
Pour les réaliser, j’ai récupéré, grâce à un scraper, l’intégralité des séances disponibles sur un site spécialisé pour la journée du 28 avril 2017. Soit plus de 20 182 séances, dans plus de 1 400 cinémas de France et de Navarre, projetant un total de 981 films différents.
Parmi ces derniers, j’en ai identifié 549 en langue étrangère (non sans mal, comme je l’explique dans un autre post sur site, où je reviens sur la méthode utilisée) pour un total de 14 223 séances, dont 2 964 en VO.
Dans certaines régions, la VO est réservée aux petites salles de centre-ville ou aux cinémas art et essai. Mais certains réseaux de multiplexes programment aussi un nombre important de séances en VO, comme UGC.
Si on passe à l’échelon des villes, c’est bien sûr à Paris que sont proposées le plus de séances en VO. Mais la banlieue et la province se défendent, avec Montreuil, Biarritz et Hérouville-Saint-Clair en tête devant la capitale si on prend compte la part totale des séances en VO.
A l’inverse, il y a des coins de France où on vous recommande pas de déménager si vous êtes #teamvo. Dans cinq départements, aucune séance en VO n’était proposée dans la journée :
- l’Ariège
- la Creuse
- la Haute-Saône
- l’Indre
- l’Orne
Les villes avec VO et les villes avec VF
Mais pourquoi les cinémas d’une ville proposent-ils de la VO alors que ceux de la ville d’à côté se contentent de la VF ? Le goût pour la VO est lié à la richesse des habitants, à leur niveau d’éducation, où bien à leur choix politique ?
Sur les 1 133 localités étudiées, plus de 65% ne proposaient aucune séance en VO dans leurs salles de cinéma. Pour explorer mes données, j’ai donc réparti la liste en deux deux camps : les villes avec VO et les villes sans VO.
J’ai ensuite associé mes résultats à une série de statistiques de l’Insee, à commencer par la population (en 2014). Sans surprise, ce sont dans les localités les plus peuplées qu’on a le plus de chances se trouver des séances en VO.
Ça semble logique : comme la majorité des Français préfère la VF, proposer de la VO n’est commercialement intéressant que si la salle se trouve dans une zone suffisamment peuplée pour qu’on y trouve un nombre suffisant d’amateurs de versions sous-titrées.
Dans les deux camps, le niveau de vie médian est proche. On peut faire l’hypothèse que la VO n’est pas « un truc de riches »…
… ce que semble confirmer la comparaison du taux de pauvreté médian des deux séries de villes.
En revanche, si on s’intéresse à la part de la population ayant suivi des études supérieures, la différence est nette.
Je vois au moins une causalité possible à cette corrélation : plus on étudie, plus on est à l’aise avec la lecture, et moins on est gêné quand on doit passer du temps à lire les dialogues en bas de l’écran. Ce qui pourrait inciter les gérants de salle de la localité concernée à privilégier les copies en VO.
J’ai aussi croisé mes données avec les résultats du premier tour de la présidentielle 2017. Les villes sans VO ont tendance à voter davantage pour Le Pen et moins pour Macron et Mélenchon que les autres. Si la présidentielle ne s’était jouée que dans les villes avec VO, Mélenchon aurait été qualifié pour le second tour.
Voilà ! Evidemment, ce travail est très parcellaire, et la méthode que j’ai utilisée sûrement contestable. Je ne suis pas spécialiste de l’étude des pratiques culturelles, et je ne sais pas si cette grande fracture française a fait l’objet d’enquêtes plus poussées. [ajout le 27/7 à 17h20 : Vodkaster a fait un point assez complet sur le sujet en 2016]
Je serais en tout cas ravi d’en savoir plus, donc n’hésitez pas à descendre donner votre avis un peu plus bas dans les commentaires, et à aller explorer ces données, qui sont disponibles dans une Google Sheet.
Corrigé le 21/7 à 10h20. Inversion des barres dans les graphique niveaux de vie et part des diplômés du supérieur.
Mis à jour le 21/7 à 11h45. Ajout du graphique consacré aux réseaux de multiplexes.
Corrigé le 1/10 à 21h10. Inversion des barres dans le graphique population.
Comment j’ai réalisé les cartes du monde selon les médias français
C’est sans doute l’expérience publiée sur ce site qui m’a donné le plus de fil à retordre. Il a fallu passer par de nombreuses et fastidieuses étapes pour arriver à la publication de la série de cartes du monde tel que le voient les médias français Dans mon labo.
Mais je suis content du rendu un peu arty de ces anamorphoses – j’ai emprunté l’idée et une partie de la méthode à Altermondes, qui en avait réalisé une à l’occasion de sa campagne de crowdfunding.
1. Scraper les résultats de recherche Google en Python
C’était la première fois que je réalisais un travail d’extraction automatique de données en concevant un script dans un langage de programmation plutôt qu’en utilisant un logiciel disposant d’une interface graphique, comme Outwit Hub.
Je me suis servi de Scrapy, un outil qui m’a beaucoup facilité la tâche, mais que je n’ai pas réussi à installer sur mon Mac (la faute à El Capitan, semble-t-il) : il a fallu ressortir un portable sous Linux pour parvenir à le lancer.
La mise au point du script m’a pris pas mal de temps, mais une fois que j’ai compris la logique, j’ai avancé relativement vite : il suffisait en effet de repérer l’endroit de la page des résultats de recherche où figure la mention « Environ x résultats ».
Le plus compliqué à été de composer avec les sécurités qui se déclenchent sur les serveurs de Google quand on le sollicite trop : même en ralentissant beaucoup le rythme du robot passant sur ces pages, je finissais toujours par voir mon adresse IP bloquée.
2. Analyser les résultats dans Google Sheets
C’est en commençant à trier et à filtrer les résultats obtenus que je me suis aperçu qu’ils n’étaient pas toujours fiables : pour certains pays, les résultats trouvés dans Google Actualités (tous médias confondus) étaient en effet ajoutés au résultats trouvés sur un média particulier…
J’ai alors tenté ma chance sur Bing, mais ce dernier ne permet pas d’effectuer une recherche combinant plusieurs termes (avec l’opérateur OR) en ciblant un nom de domaine particulier.
De retour sur Google, j’ai fini par obtenir des données cohérentes en limitant la recherche aux pages publiées lors de l’année écoulée.
Il a fallu aussi traiter quelques cas particuliers – par exemple, le mot « Canada » apparaît sur toutes les pages du Huffington Post et de Buzzfeed, ces deux sites proposant un accès vers leur édition canadienne.
Il reste sans doute de petites aberrations de ce genre dans les données utilisées pour faire les cartes, mais j’ai considéré qu’elles n’étaient pas préjudiciables, vu la taille finale des cartes et leur niveau important de déformation.
3. Ajouter les résultats obtenus à une carte du monde grâce à QGIS
Le logiciel de cartographie avancé QGIS m’a permis d’ouvrir un shapefile (fichier de contours) trouvé sur ThematicMapping et de lui associer mes propres données via des recherches verticales dans la table.
Pour que ça marche, il faut une clé commune aux deux fichiers : en l’occurence, le code ISO à trois chiffres, que j’avais pris soin d’utiliser pour chaque pays étudié – je l’ajoute désormais systématiquement à toutes mes feuilles de calcul quand elles sont basées sur des pays, une précaution qui se révèle souvent utile.
4. Réaliser les anamorphoses avec ScapeToad
Disponible sur tous les OS via Java, ScapeToad est un petit logiciel plutôt bien fichu qui va réaliser la déformation du fichier shapefile en tenant compte, pour chaque pays, d’une valeur numérique disponible dans la table associée au fichier de contours.
Le résultat peut être enregistré au format d’image vectoriel SVG, ce qui permet de l’utiliser ensuite à n’importe quelle taille.
Attention : pour une carte du monde, les temps de calcul et de sauvegarde sont importants (surtout quand il faut recommencer la manipulation vingt fois pour vingt médias différents…).
5. Améliorer le résultat dans Adobe Illustrator
Le fichier SVG obtenu peut être facilement ouvert et modifié dans Illustrator, ce qui m’a permis de changer la couleur et la transparence des pays, et de créer une version PNG utilisée pour le partage Facebook.
Une fois les vingt cartes obtenues, j’ai créé la petite infographie permettant de basculer d’un média à l’autre en HTML, CSS et JQuery. Enfin, j’ai utilisé Datawrapper pour réaliser les deux graphiques également présents dans l’article.