
Comme souvent pour les projets que je mène Dans mon labo, ma petite enquête autour des chroniques de Bernard Guetta sur France Inter m’a amené à utiliser toute une panoplie d’outils. Je les passe rapidement en revue dans cet article, en espérant que ça vous aide pour vos propres travaux.
1. Récupérer le texte des chroniques avec Outwit Hub
Cette première étape a été rapide, la construction du site de France Inter le rendant très simple à « scraper ». Une page d’archives propose en effet des liens vers chacune des chroniques. Je l’ai chargée dans Outwit Hub puis ai demandé à ce dernier d’attraper toutes les URL concernés (elles contiennent toutes la chaîne de caractères « emission-geopolitique »).
Toujours dans Outwit Hub, j’ai ensuite mis au point un scraper pour extraire les éléments intéressants du code HTML de la page, à commencer par le texte. Vous pouvez télécharger cet extracteur (c’est un petit fichier XML) et l’importer dans Outwit Hub si vous souhaitez faire un travail similaire avec d’autres contenus publiés sur le site de France Inter.
2. Nettoyage des textes avec Open Refine
Les textes récupérés étaient globalement propres. Open Refine m’a cependant permis de supprimer de mon échantillon les chroniques du remplaçant de Bernard Guetta, Anthony Bellanger (classées dans la même rubrique sur le site de France Inter), ainsi que quelques entrées sans texte (correspondant à des pages vides sur le site).
J’ai également également pu retirer le code du lecteur vidéo Dailymotion parfois présent en haut des textes.
3. Décompte des pays dans Google Sheet
Une fois les données nettoyées, je les ai exportées au format CSV et importées dans le tableur Google Sheet. J’ai ajouté une feuille avec une liste des pays du monde compilée par Wikipedia.
Dans cette deuxième feuille, j’ai pu chercher, grâce à la fonction COUNTIF, les occurences de chaque pays dans la colonne concernée de la première feuille.
J’ai fait quelques tests et passé en revue la liste pour traiter quelques cas particuliers. Par exemple, pour la Birmanie, le mot Myanmar est parfois utilisé ; le Nigéria est parfois écrit « Nigeria » ; le mot Congo peut désigner deux pays, le Congo-Brazzaville ou le Congo-Kinshasa : le mot Hollande est un pays mais aussi un président français…
Il n’est d’ailleurs pas exclu qu’il reste des erreurs après ce traitement, n’hésitez pas à me contacter si vous pensez en avoir décelé.
4. Croisement avec les données de la Banque mondiale
Un module complémentaire de Google Sheet m’a permis de traduire automatiquement les cellules contenant le nom du pays du français vers sa version anglaise.
J’ai récupéré la liste des codes ISO à trois caractères des pays du monde, et grâce à la fonction VLOOKUP, j’ai pu attribuer le bon code ISO à chaque pays de ma propre liste, non sans une série de corrections « à la main ».
Le tout est un peu fastidieux, mais quand cette manipulation fini, c’est magique : avec comme clé commune le code ISO, il devient facile de croiser un tel fichier avec des centaines d’autres disponibles sur le Web.
Le site de la Banque mondiale contient ainsi des séries de données sur beaucoup d’indicateurs : population, superficie, PIB… Et le tableau qu’on télécharge contient aussi le code ISO, la fonction VLOOKUP permet donc de faire le rapprochement automatiquement et sans risque d’erreur.
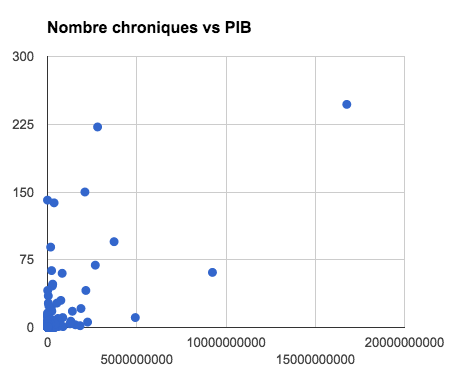
J’ai ensuite utiliser la fonction CORREL de Google Sheet pour chercher très facilement des corrélations (par exemple entre la population d’un pays et le nombre de fois où il est cité) d’une colonne de mon document à l’autre.
5. Réalisation de la carte avec TileMill
Je ne vais pas m’étendre sur cette partie du travail, d’autant que TileMill n’est plus maintenu – il est censé être remplacé par Mapbox Studio, logiciel que j’ai testé et que je n’aime pas trop.
je suis parti du shapefile contenant les délimitations de chaque pays (y compris les zones contestées, comme le Somaliland ou le Sahara occidental, ce qui peut être source de problèmes), et j’ai pu insérer dans le fichier DBF associé des colonnes contenant mes propres données – non sans mal.
L’avantage de TileMill, c’est qu’il permet de une configuration très précise de la carte, des couleurs avec lesquelles « colorier » les pays au design des info-bulles, en passant par le niveau de détails souhaité à chaque niveau de zoom.
L’inconvénient, c’est que tout ça prend beaucoup de temps, au point que je ne sais pas si je recommanderai un outil aussi sophistiqué pour un travail plus régulier au sein d’une rédaction.
J’ai l’impression qu’aucune solution de cartographie actuelle ne donne pleinement satisfaction quand on est plus un bricoleur qu’un développeur, mais vous avez peut-être de bons tuyaux à échanger dans les commentaires.
La carte créée dans TileMill s’exporte facilement dans un compte Mapbox, depuis lequel on récupère le code d’intégration, sous forme d’iframe et avec quelques options intéressantes, comme la désactivation du zoom via la molette de la souris.
6. Etude des textes avec le logiciel de lexicométrie TXM
C« était la partie la plus nouvelle pour moi dans ce processus : tester des outils de lexicométrie. Le sociologue Baptiste Coulmont, que je remercie au passage, m’a conseillé sur Twitter d’essayer TXM, logiciel prisé des chercheurs dans ce domaine.
J’ai dû passer par pas mal de tutoriels et de guides, pour apprendre par exemple à « étiqueter » un corpus de texte, afin de trier les mots entre adjectifs, adverbes, verbes… Au passage, j’ai appris des mots rigolos comme « hapax » ou « lemmatisation ».
Les fonctionnalités qui m’ont le plus bluffé sont l’affichage des concordances (les mots qui précèdent ou suivent chaque occurence d’un mot donné du texte) et celle des cooccurrences (les mots qui se retrouvent souvent au voisinage d’un mot donné du texte).
Mais si les possibilités de cet outils semblent passionnantes, je recommande pas mal de patience à ceux qui veulent s’y coller.
7. Réalisation des graphiques avec Datawrapper
Pas grand chose à signaler ici : j’ai préparé mes tableaux dans Google Sheet, je les ai copiés/collés dans Datawrapper et j’ai pu fignoler la présentation des graphiques que vous avez vus.
Précision : l’intégration d’un graphique sur son propre site requiert désormais la souscription à un abonnement payant, décision que lequel Mirko Lorenz a expliquée sur le blog de la société.
Voilà ! Il y avait sans doute bien plus simple pour arriver au même résultat, et je compte d’ailleurs sur vos conseils dans les commentaires ci-dessous.
Je ne peux publier le corpus sur lequel j’ai travaillé (ce serait une forme de reproduction sans autorisation des textes), mais vous pouvez télécharger une synthèse par pays ou bien me contacter pour obtenir l’ensemble de mes données.
