C’est sans doute le projet le plus ambitieux et le plus complexe que j’aie mené à bien depuis que j’ai lancé Dans mon labo il y a bientôt quatre ans. Il m’a fallu pas mal d’après-midi pluvieux et de jours fériés blafards pour terminer le tableau de bord qui liste les sujets les plus présents dans les sites d’actualité français.
Il est devenu possible grâce aux progrès que j’ai réalisés en Python, un langage de programmation prisé des datajournalistes. De mon côté, j’ai dû sérieusement m’y mettre courant 2017, notamment pour afficher en direct les résultats des élections législatives au sein de la carte interactive que j’ai préparée pour Contexte.
Pour explorer les flux XML mis à disposition par le ministère de l’Intérieur le soir des scrutins, j’ai trouvé en Python, avec sa syntaxe accessible et ses multiplies librairies disponibles, un partenaire idéal. (Mais il est aussi possible de faire ça très bien avec d’autres solutions, comme R.)
Et ces connaissances m’ont ouvert de nouveaux horizons, notamment ceux de la reconnaissance automatisée d’entités nommées. Un domaine qui, m’a-t-on expliqué, a beaucoup progressé grâce au patient travail de description et de classement réalisé par les contributeurs de Wikipedia.
J’ai d’abord travaillé, toujours pour Contexte, sur les thématiques les plus présentes dans le discours des députés pour enrichir le trombinoscope de l’Assemblée nationale que le site propose à ses abonnés. C’est alors que m’est venue l’idée de proposer une démarche comparable, mais avec les médias en ligne.
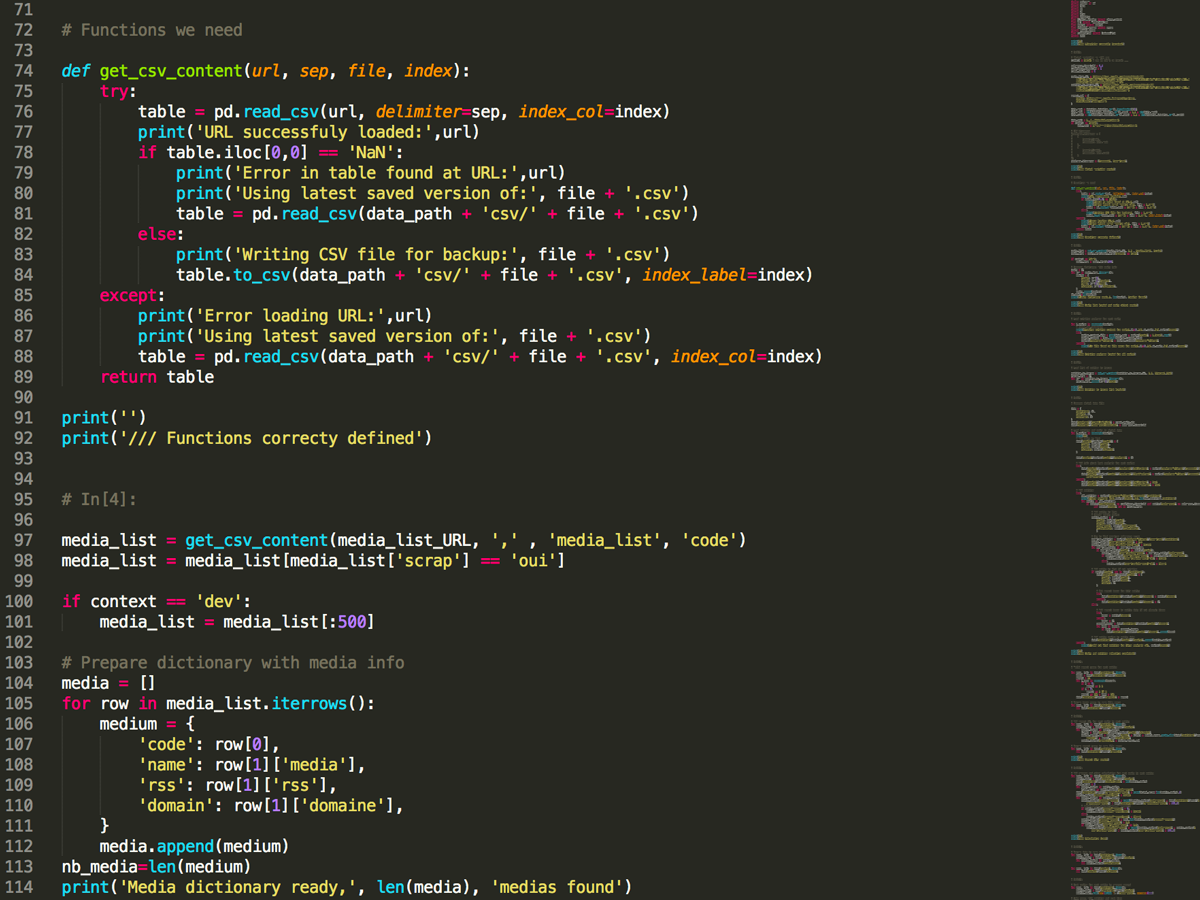
1. Scraper les flux RSS des sites d‘actu avec Python
J’ai listé, dans une Google Sheet, les sites que je souhaitais étudier, en renseignant pour chacun l’adresse de son flux RSS principal.
Mon script de scraping (dispo pour les curieux) commence par récupérer cette liste, et va chercher dans chaque flux le titre et la description (le chapô ou le début du texte) de chaque article. Il récupère aussi sa date de publication, et enregistre le tout dans un fichier Json dédié à chaque site.
Tous les flux RSS n’étant pas construits de la même façon, il a fallu prendre en compte les différents cas de figure : ainsi, le résumé de l’article se trouve dans un élément qui peut être nommé « description », « summary », « content »…
2. Créer un corpus de textes et le faire analyser par TextRazor
La suite de ce script va concaténer ensemble les titres et résumés de chaque article publiés dans une période donnée pour en faire un seul et même texte.
Ce corpus va ensuite être envoyé à TextRazor, via la librairie Python que met à disposition ce service d’analyse sémantique. Ce dernier est gratuit jusqu’à 500 requêtes par jour, un quota largement suffisant pour ce projet.
Parmi les services équivalents, TextRazor a un autre avantage : non seulement son outil d’extraction des entités nommées renvoie la liste des thématiques détectées au sein du corpus soumis, mais il fournit aussi pour chacune un score de relevance (« pertinence », que j’ai finalement traduit en « présence » dans mon tableau de bord).
Ainsi, s’il détecte les mots « GPA », « gestation pour autrui » ou « mère porteuse » dans un texte, Textrazor réunit ses expressions dans une seule thématique (en général le titre de la notice Wikipedia dédiée). Et donne à cette dernière une note, de 0 à 1, selon que l’entité lui semble plus ou moins pertinente dans le texte fourni.
C’est à la fois la force et la faiblesse de ma méthode : ce scoring me permet de générer les multiples classements, mais je n’ai pas « la main » sur son élaboration.
Malgré quelques mauvaises surprises, l’observation des résultats obtenus m’a toute fois rassuré : Le Parisien est en général le média où le thème « Paris » est le plus présent ; on retrouve souvent « Jean-Luc Mélenchon » bien classé dans les résultats de Politis ; Sputnik et RT France sont bien placés au classement pour le thème « Vladimir Poutine ».
4. Héberger les scripts sur un serveur chez PythonAnywhere
Cette partie-là du chantier serait une promenade de santé pour un développeur back-end même débutant. A un journaliste bidouilleur comme moi, elle a pris pas mal de temps et d’énergie.
Une fois le script Python décrit ci-dessus terminé, je ne pouvais pas l’exécuter moi-même plusieurs fois par jour sur mon ordinateur afin de disposer de données toujours fraîches pour alimenter un éventuel tableau de bord.
Sur les conseils d’amis développeurs, j’ai regardé plusieurs offres d’hébergement comme Amazon Web Services ou Google Cloud Platform, mais la longueur des procédures d’installation et des tutoriels proposés m’a vite refroidi. Je me suis rabattu sur Python Anywhere. un service peu onéreux et qui s’est révélé mieux adapté à un noob comme moi.
Même avec cette solution, je suis passé par mal, de guides d’utilisation, de pages d’aide et de questions Stack Overflow avant d’arriver mes fins : faire tourner mon script de scraping plusieurs fois par jour.
4. Créer le tableau de bord en front à partir d’un fichier Json optimisé
Une fois toutes ces listes de thématiques récupérées et enregistrées dans le fichier Json de chaque média, un autre script Python, lui aussi hébergé sur PythonAnywhere, va préparer un fichier Json commun et de taille réduite.
Ce dernier sera récupéré, au moment où le tableau de bord publié Dans mon labo se charge, par votre navigateur. Au final, c’est donc Chrome, Firefox ou Edge qui va construire l’infographie à l’intérieur de la page.
Je ne détaillerais pas sur ce travail de développement front-end, classique combinaison de HTML, de CSS et de Javascript, mais si vous avez des questions sur cette partie, je serai ravi d’y répondre !
A ce stade, la principale difficulté pour moi a été de s’assurer que le chargement des données puis la construction de l’infographie se fasse dans un délai raisonnable : lors des premières étapes, le tout prenait parfois une bonne dizaine de secondes, ce qui es rédhibitoire.
Pour chaque média, j’ai choisi de ne pas intégrer une thématique si son score était inférieur à un certain seuil (en ce moment, 0,4/1), et de n’afficher une thématique dans la liste principale que si elle était présente dans au moins quatre médias.
Il m’a fallu pas mal d’allers-retours entre scripts Python sur le serveur et code Javascript dans le navigateur pour réduire ce délai et obtenir une expérience suffisamment fluide, mais il reste sans doute pas mal d’optimisation possible.
5. Préparer la suite avec des analyses hebdomadaires et mensuelles
Comme beaucoup l’ont fait remarquer dès la publication du tableau de bord, les résultats seront intéressants à observer dans le temps, au-delà de la photographie actuelle (les sept derniers jours). Mon script réalise déjà des analyses hebdomadaires et mensuelles, qui ne sont pas affichées mais que j’espère utiliser quand j’aurais davantage de recul. (Edit le 5 octobre : des graphiques s’affichent désormais pour chaque thématique, j’y reviens dans un thread sur Twitter)
Voilà ! Je suis en tout cas curieux de savoir vos remarques, critiques ou propositions d’amélioration dans les commentaires de ce post ou bien, pour les timides, dans un message privé.
Mis à jour le 2/2 à 10h15. Précision sur les seuils (point 4) et point 5 ajouté.
