Les médias nous donnent-ils une vision déformée du monde qui nous entoure ? La question est vieille comme Théophraste Renaudot, mais j’ai tenté d’y apporter une réponse moderne avec la série de cartes « anamorphosées » publiée ci-dessous – une idée que j’ai piquée à mes petits camarades d’Altermondes.
Elles ont été réalisées en basant la déformation de chaque pays sur le nombre de résultats trouvés par Google quand on le cherche sur le site de l’un des vingt médias étudiés – je reviens plus en détail sur la méthode utilisée (et ses limites) dans un autre post.
Avec l’avènement des réseaux sociaux, devenus pour beaucoup d’entre nous le principal point d’accès à l’information, ces cartes vont-elles se déformer davantage ?
En filtrant selon leur popularité les publications venues de nos amis et des pages auxquelles nous nous sommes abonnés , Facebook est en effet accusé de créer une « bulle » autour de ses utilisateurs, ne les exposant plus qu’à des informations qui les touchent ou les font réagir.
Et comme leur trafic dépend de plus en plus de cette plateforme, les médias sont tentés de « publier pour Facebook », laissant de côté l’actualité des pays trop lointains. Un phénomène qu’on peut observer sur les cartes de Buzzfeed France et du Huffington Post, où les pays du Sud occupent la portion congrue.
Mais ces biais ne sont pas nouveaux, et ils dépendent aussi de la ligne éditoriale des journaux concernés :
L’Amérique du Sud et l’Afrique sont nettement enflées sur la carte du Monde diplomatique – logique vu les positions tiers-mondistes de ce mensuel.
l’Europe explose sur celle de Contexte – normal, le site suit de près l’actualité législative de l’UE.
les Etats-Unis sont bien plus gros que la moyenne sur celle de Slate.fr – pas étonnant, une bonne partie des articles sont des traductions de textes publiés dans la version américaine.
Les sites qui reprennent beaucoup l’AFP, par exemple Libération et Le Figaro, ont des cartes assez proches –une part importante des résultats décomptés se trouvent dans les dépêches de cette agence et reprises, sous différentes formes, sur ces sites.
Ces spécificités se retrouvent si on s’intéresse aux pays les plus cités, média par média.
On retrouve bien la loi du « mort-kilomètre », qui veut qu’une tempête de neige à Londres pourra occuper les chaînes infos toute la journée, alors qu’un tsunami en Indonésie peut faire des centaines de victimes sans qu’on chamboule le menu des journaux télévisés.
Mais on peut aussi prendre le problème dans l’autre sens, et s’intéresser aux médias qui s’intéressent plus (ou moins) que la moyenne à un pays donné.
Un eBook ouvert sur un iPhone (Jonas Tana/Flickr/CC-BY-NC-DR)
Ça coûte combien, une série de 0 et de 1 ? C’est la vertigineuse question à laquelle se confrontent les éditeurs quand il faut fixer le prix de la version électronique d’un de leurs livres.
Et la réponse varie beaucoup d’un titre à l’autre, comme le montre un échantillon d’une cinquantaine de romans et essais, choisi parmi les plus vendus ou signés des auteurs les plus connus.
Pour chacun, j’ai relevé le prix de l’édition originale, celui de l’édition poche et celui des versions iBook d’Apple ou Kindle d’Amazon (données disponibles au format CSV).
A ma grande surprise, l’ebook est dans la plupart des cas plus cher que la version poche.
Le surcoût atteint même 10,90 € pour Boomerang, de Tatiana de Rosnay (éd. Héloïse d’Ormesson) – 17,99 € en version électronique, 7,10 € au Livre de poche (+150%).
De même, Apocalypse Bébé, de Virginie Despentes (éd. Grasset), vous coûtera 13,99 € si vous souhaitez le lire sur votre Kindle, contre 7,10 € seulement si vous voulez feuilleter les 380 pages de la version Livre de poche (+97%).
Ce décalage m’a étonné : d’un côté, un fichier numérique dont la reproduction ne coûte rien ; de l’autre, un objet physique fait de papier et d’encre et qu’il faut acheminer jusqu’au lecteur.
Sans compter que proposer un prix bas pour les ebooks les rend plus accessibles aux lecteurs les plus fauchés, et pourrait éviter de voir certains se tourner avec le piratage.
Si on compare le prix de l’édition originale et celui de l’ebook, le second est toujours moins élevé, mais la décote est très variable selon les titres : de ‑17% à ‑68% (-41% en moyenne).
Parmi les auteurs dont les ebooks sont vendus à prix cassés, on trouve paradoxalement Frédéric Beigbeder, un farouche opposant du livre électronique – c’est la fin « des librairies, des maisons d’édition, des suppléments littéraires dans les journaux et peut-être la fin de la critique littéraire », déclarait-il sur Europe 1 en 2011.
Son Oona & Salinger est vendu 7,10 € en poche mais seulement 6,49 € chez Apple et Amazon, soit une remise de 9%, la plus élevée de mon échantillon. Et pour Windows on the World, l’ebook est « seulement » 39 centimes plus cher que le poche (7,99 € au lieu de 7,60 €, soit +5%).
J’ai donc contacté les maisons d’édition concernées pour mieux comprendre comment ces prix étaient fixés.
La réponse de Fallois m’a beaucoup surpris : si La Vérité sur l’affaire Harry Québert, best-seller surprise de Joël Dicker, coûte 11,99 € en version électronique (contre 9,20 € en poche, soit +30%), c’est pour éviter qu’elle se vende trop bien, m’explique en substance Philippine Cruse :
« Nous voulons soutenir le livre papier. Si vous mettez un prix trop bas pour les ebooks, les gens ne vont acheter que du numérique et vous allez faire mourir les libraires. »
Si le sort des librairies est en jeu, pourquoi ne pas aller plus loin et retirer la version ebook de la vente ? Parce que l’époque est au compromis : « On est obligés de jongler, c’est une période un peu difficile », reconnaît-elle.
Chez Viviane Hamy, qui vend Coule la Seine de Fred Vargas à 9,99 € en ebook alors qu’il coûte 4,30 € en poche (+132%), Maylis Vauterin a bien voulu détailler la politique tarifaire pratiquée.
Quand le livre est une nouveauté, la décote sera de « 30% au minimum », mais le prix pourra même être descendu à 9,99 € dans le cadre d’une offre de lancement si « le potentiel d’un titre est particulièrement fort pour les lecteurs qui lisent en numérique ».
Pour les livres « de fond », le prix est « de 9,99 € pour la collection policière et 6,99 € pour la collection bis », hors périodes et offres de promotion.
Et c’est justement pour pouvoir proposer des promos que le prix de Coule la Seine et des autres romans de cet éditeur est maintenu plus cher que la version poche :
« Je ne connais pas d’autres mécanismes pour mettre en avant nos livres (dans la masse de livres disponibles, en étant un éditeur indépendant face à des groupes) que de participer à des opérations de baisse de prix.
En pratiquant un prix normal de 9,99 €, j’ai ainsi la possibilité de les proposer à 4,99 € en négociant de beaux focus sur notre production. »
Vauterin reconnaît qu’elle « tâtonne » pour « trouver un modèle éditorial » permettant de maintenir en ligne le délicat équilibre entre « best-sellers et découvertes de talents, forcément déficitaires au plan économique ».
Mais s’il est virtuel, un livre électronique engendre des coûts bien réels pour l’éditeur, ajoute-t-elle. Les revendeurs (Apple, Amazon…) gardent 40% du prix payé par l’acheteur. L’éditeur a choisi de verser des droits d’auteurs plus élevés que pour le papier. Et puis il faut prendre en compte « l’interface vers les plate-formes et la gestion des métadonnées, qui supposent de gros investissements ». Sans oublier la réalisation des fichiers epub eux-mêmes.
Elle se défend en tout cas de toute hostilité envers ces nouveaux supports :
« Le numérique est une part importante de la vie de notre catalogue. Nous avons investi afin de rendre disponible près de 80% de notre catalogue en numérique, y compris des ouvrages qui vendent de très petites quantités. »
Et pour vous, quel est le bon prix pour un livre électronique ? Le débat est ouvert dans les commentaires !
L’actualité de ces dernières heures est particulièrement chargée, entre les attaques de l’Etat islamique, le référendum annoncé en Grèce et la décision de la Cour suprême américaine de légaliser le mariage homosexuel.
Dans ces conditions, pas simple de choisir le sujet de couverture d’un quotidien ou l’ordre des sujets affichés en page d’accueil d’un site d’information.
Mais la « hiérarchie de l’info » chère aux journalistes ne dépend pas qu’à des critères objectifs, loin de là. L’importance qu’une rédaction accorde à un sujet dépend aussi de sa vision du monde, de ses priorités éditoriales et de ses valeurs.
Je me suis amusé à comparer les pages d’accueil des sites des chaînes américaines MSNBC (classée pro-démocrate, « libérale » au sens américain, à gauche donc) et Fox News (pro-républicain, conservateur, à droite donc). Les captures d’écran ont été prises ce samedi matin.
Vu l’importance du sujet, je m’attendais à ce qu’il occupe à peu près la même place sur les deux sites, mais on voit que Fox News préfère mettre en avant d’autres actualités (une forme de déni ?), surtout en haut de page d’accueil. De façon plus attendue, les titres choisis par les deux médias donnent clairement la couleur.
Titres de MSNBC.
L’Amérique ouvre un nouveau chapitre de son histoire
Les mots de la Cour suprême dans sa décision
Des émeutes à la célébration
L’avis d’une sénatrice gay sur « cette étape capitale »
La plus belle semaine de tous les temps pour le camp progressiste
Titres de Fox News, en haut de page :
« Une cour de justice n’est pas le législateur », explique le juge John Roberts, qui avait soutenu Obamacare
Vidéo : le mariage pour tous a gagné
Edito : la cour s’attaque à la vérité du mariage et dresse la foi contre la loi
Titres de Fox News, beaucoup plus bas dans la page, affichés seulement après avoir « scrollé » suffisamment :
Mariage gay : pourquoi la Cour suprême a tort.
Pourquoi les décisions de la Cour suprême sur Obamacare, le mariage gay, le droit de propriété… vont aider les Républicains à la présidentielle de 2016
Cour suprême : les couples de même sexe peuvent se marier dans les 50 Etats
Comment le mariage gay va affecter l’Amérique
Les avertissements du juge Roberts après la victoire du mariage gay
Ben & Jerry sortent une crème glacée spéciale après la victoire du mariage gay.
Les réactions des célébrités à la décision de la Cour suprême
Mike Huckabee s’en prend au jugement de la Cour suprême
Pour Ric Grenell, la décision sur mariage gay est une grande victoire pour les conservateurs.
Quel impact aura la décisions sur la course à la Maison-Blanche
Lea DeLaria sur l’impact de la décision de la Cour suprême
La liste des chroniques de Bernard Guetta dans Google Sheet.
Comme souvent pour les projets que je mène Dans mon labo, ma petite enquête autour des chroniques de Bernard Guetta sur France Inter m’a amené à utiliser toute une panoplie d’outils. Je les passe rapidement en revue dans cet article, en espérant que ça vous aide pour vos propres travaux.
1. Récupérer le texte des chroniques avec Outwit Hub
Cette première étape a été rapide, la construction du site de France Inter le rendant très simple à « scraper ». Une page d’archives propose en effet des liens vers chacune des chroniques. Je l’ai chargée dans Outwit Hub puis ai demandé à ce dernier d’attraper toutes les URL concernés (elles contiennent toutes la chaîne de caractères « emission-geopolitique »).
Toujours dans Outwit Hub, j’ai ensuite mis au point un scraper pour extraire les éléments intéressants du code HTML de la page, à commencer par le texte. Vous pouvez télécharger cet extracteur (c’est un petit fichier XML) et l’importer dans Outwit Hub si vous souhaitez faire un travail similaire avec d’autres contenus publiés sur le site de France Inter.
2. Nettoyage des textes avec Open Refine
Les textes récupérés étaient globalement propres. Open Refine m’a cependant permis de supprimer de mon échantillon les chroniques du remplaçant de Bernard Guetta, Anthony Bellanger (classées dans la même rubrique sur le site de France Inter), ainsi que quelques entrées sans texte (correspondant à des pages vides sur le site).
J’ai également également pu retirer le code du lecteur vidéo Dailymotion parfois présent en haut des textes.
Dans cette deuxième feuille, j’ai pu chercher, grâce à la fonction COUNTIF, les occurences de chaque pays dans la colonne concernée de la première feuille.
J’ai fait quelques tests et passé en revue la liste pour traiter quelques cas particuliers. Par exemple, pour la Birmanie, le mot Myanmar est parfois utilisé ; le Nigéria est parfois écrit « Nigeria » ; le mot Congo peut désigner deux pays, le Congo-Brazzaville ou le Congo-Kinshasa : le mot Hollande est un pays mais aussi un président français…
Il n’est d’ailleurs pas exclu qu’il reste des erreurs après ce traitement, n’hésitez pas à me contacter si vous pensez en avoir décelé.
4. Croisement avec les données de la Banque mondiale
Un module complémentaire de Google Sheet m’a permis de traduire automatiquement les cellules contenant le nom du pays du français vers sa version anglaise.
J’ai récupéré la liste des codes ISO à trois caractères des pays du monde, et grâce à la fonction VLOOKUP, j’ai pu attribuer le bon code ISO à chaque pays de ma propre liste, non sans une série de corrections « à la main ».
Le tout est un peu fastidieux, mais quand cette manipulation fini, c’est magique : avec comme clé commune le code ISO, il devient facile de croiser un tel fichier avec des centaines d’autres disponibles sur le Web.
Le site de la Banque mondiale contient ainsi des séries de données sur beaucoup d’indicateurs : population, superficie, PIB… Et le tableau qu’on télécharge contient aussi le code ISO, la fonction VLOOKUP permet donc de faire le rapprochement automatiquement et sans risque d’erreur.
Exemple de nuage de points dans Google Sheet
J’ai ensuite utiliser la fonction CORREL de Google Sheet pour chercher très facilement des corrélations (par exemple entre la population d’un pays et le nombre de fois où il est cité) d’une colonne de mon document à l’autre.
5. Réalisation de la carte avec TileMill
Je ne vais pas m’étendre sur cette partie du travail, d’autant que TileMill n’est plus maintenu – il est censé être remplacé par Mapbox Studio, logiciel que j’ai testé et que je n’aime pas trop.
je suis parti du shapefile contenant les délimitations de chaque pays (y compris les zones contestées, comme le Somaliland ou le Sahara occidental, ce qui peut être source de problèmes), et j’ai pu insérer dans le fichier DBF associé des colonnes contenant mes propres données – non sans mal.
L’avantage de TileMill, c’est qu’il permet de une configuration très précise de la carte, des couleurs avec lesquelles « colorier » les pays au design des info-bulles, en passant par le niveau de détails souhaité à chaque niveau de zoom.
L’inconvénient, c’est que tout ça prend beaucoup de temps, au point que je ne sais pas si je recommanderai un outil aussi sophistiqué pour un travail plus régulier au sein d’une rédaction.
J’ai l’impression qu’aucune solution de cartographie actuelle ne donne pleinement satisfaction quand on est plus un bricoleur qu’un développeur, mais vous avez peut-être de bons tuyaux à échanger dans les commentaires.
La carte créée dans TileMill s’exporte facilement dans un compte Mapbox, depuis lequel on récupère le code d’intégration, sous forme d’iframe et avec quelques options intéressantes, comme la désactivation du zoom via la molette de la souris.
6. Etude des textes avec le logiciel de lexicométrie TXM
C« était la partie la plus nouvelle pour moi dans ce processus : tester des outils de lexicométrie. Le sociologue Baptiste Coulmont, que je remercie au passage, m’a conseillé sur Twitter d’essayer TXM, logiciel prisé des chercheurs dans ce domaine.
J’ai dû passer par pas mal de tutoriels et de guides, pour apprendre par exemple à « étiqueter » un corpus de texte, afin de trier les mots entre adjectifs, adverbes, verbes… Au passage, j’ai appris des mots rigolos comme « hapax » ou « lemmatisation ».
Les fonctionnalités qui m’ont le plus bluffé sont l’affichage des concordances (les mots qui précèdent ou suivent chaque occurence d’un mot donné du texte) et celle des cooccurrences (les mots qui se retrouvent souvent au voisinage d’un mot donné du texte).
Mais si les possibilités de cet outils semblent passionnantes, je recommande pas mal de patience à ceux qui veulent s’y coller.
7. Réalisation des graphiques avec Datawrapper
Pas grand chose à signaler ici : j’ai préparé mes tableaux dans Google Sheet, je les ai copiés/collés dans Datawrapper et j’ai pu fignoler la présentation des graphiques que vous avez vus.
Précision : l’intégration d’un graphique sur son propre site requiert désormais la souscription à un abonnement payant, décision que lequel Mirko Lorenz a expliquée sur le blog de la société.
Voilà ! Il y avait sans doute bien plus simple pour arriver au même résultat, et je compte d’ailleurs sur vos conseils dans les commentaires ci-dessous.
Je ne peux publier le corpus sur lequel j’ai travaillé (ce serait une forme de reproduction sans autorisation des textes), mais vous pouvez télécharger une synthèse par pays ou bien me contacter pour obtenir l’ensemble de mes données.
Ça se passe au moment où la tartine beurrée entre en contact avec le café brûlant. Un ronronnement s’échappe du poste de radio. Une voix familière qui chevrote un peu, un phrasé impeccable qui franchit les « premièrement », les « deuxièmement » et les « mais également » sans jamais trébucher. Le texte, lui, glisse sans cahot d’une conférence genevoise à une réunion du G7, en passant par Bruxelles et ses sommets de la dernière chance.
Une chronique quotidienne depuis 1991
Bernard Guetta, 64 ans, est « un majestueux monument à dômes et à coupoles […] installé dans le paysage matinal »,s’amusait Daniel Schneidermann. S’il le taquine, le fondateur d’Arrêt sur images voit aussi en lui l’un des rares journalistes qui « dans chaque événement microscopique cherchent par réflexe les racines profondes, les lointaines conséquences, bref la perspective ».
Le chroniqueur a rejoint France Inter en 1991 après une carrière déjà longue et tient depuis la chronique Géopolitique chaque matin, du lundi au vendredi à 8h19. Ce passage obligé de la matinale est inscrit dans la routine des auditeurs, sur le mode « déjà Guetta, faut y aller, Matteo va être en retard à l’école ».
Près de trois saisons de chroniques pour un imposant corpus de plus de 300 000 mots (pour vous donner une idée, ça fait un tiers de plus que le Nouveau Testament), soit 1,6 million de signes ou encore plus de 1 000 feuillets.
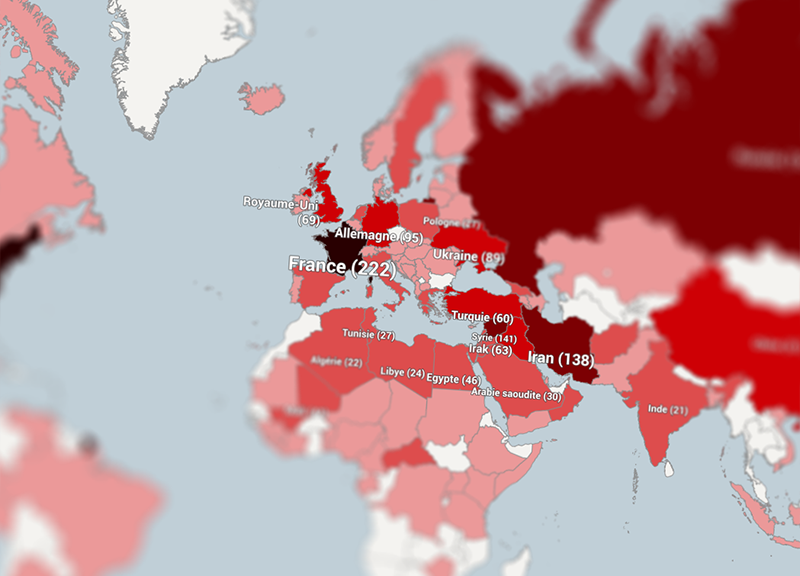
La carte en haut de cette page montre le résultat de ses recherches (contactez-moi ou laissez un commentaire si vous avez remarqué une erreur ou une bizarrerie). Je les ai également rassemblées sous forme de classements.
En se promenant sur la planète de Bernard Guetta, on remarque bien sûr la domination des Etats-Unis, cités dans un près d’une chronique sur deux. Mais la Russie, le Proche-Orient et le Moyen-Orient sont aussi bien servis par le chroniqueur. Logique, vu l’actualité de ces trois dernières années en Ukraine, en Syrie et dans le reste du monde arabe.
Les pays émergents sont moins bien lotis : la Chine n’a été citée que 61 fois, et l’Inde (21 ) comme le Brésil (6) ne semblent guère passionner le chroniqueur.
Même relatif désintérêt pour l’Afrique, surtout si on met de côté les pays où la France est intervenue militairement (Libye, Mali, Centrafrique) – le Nigéria, devenu pourtant la première économie d’Afrique n’est cité que sept fois. Ou pour l’ensemble Amérique latine, malgré les remuants dirigeants du Venezuela, de la Bolivie et de l’Equateur.
« Eclairer les événements, les hiérarchiser »
Loin des yeux, loin du cœur de Guetta ? L’Indonésie, malgré ses 250 millions d’habitants, n’est mentionnée qu’une seule fois, l’Australie et l’Afrique du Sud trois fois seulement.
A l’inverse, de petits pays sont l’objet d’une plus grande attention, comme le Liban, présent dans 35 chroniques, l’Arménie (7) et bien sûr le Vatican (7).
Devant ces chiffres parfois étonnants, Bernard Guetta m’explique qu’il n’est « pas un universitaire », qu’il n’a pas vocation « à passer en revue les plus de 200 pays présents l’ONU », mais qu’il entend, en bon journaliste, « éclairer les événements les plus marquants et les hiérarchiser ».
Le chroniqueur explique ne pas chercher, au fil de ses interventions, un équilibre entre les différentes régions du monde. « C’est l’actualité qui commande », résume-t-il, ajoutant :
« Je vous mets en garde contre la tentation de tirer des conclusions basées seulement sur le nombre d’occurrences, pour moi ce n’est pas pertinent. »
Thaïlande, Maroc, Birmanie : rien
Mais ce qui m’a le plus surpris, ce sont les trous du gruyère : en effet, la liste des pays qui n’ont jamais cités en plus de 500 chroniques comprend quelques poids lourds.
C’est le cas de la Thaïlande, qui a pourtant connu, sur la période étudiée, une crise politique majeure débouchant sur une reprise en main du pays par l’armée. Mais aussi de la Birmanie, dont le régime donne des signes d’ouverture depuis la libération d’Aung San Suu Kyi en 2010.
Plus frappant encore, le cas du Maroc, où Guetta a pourtant passé une partie de sa jeunesse – l’Algérie voisine est elle mentionnée 22 fois. Ces absences ne perturbent cependant pas l’intéressé :
« Tout dépend de la période que vous étudiez. Il n’était pas illogique que je n’aie pas parlé du Maroc ces derniers temps, il n’y avait pas d’actualité importante dans ce pays.
La brouille avec la France [après que le chef du contre-espionnage marocain Abdellatif Hammouchi a été convoqué par un juge français lors d’un voyage à Paris, ndlr] n’a pas duré très longtemps.
J’en aurais peut-être parlé si personne ne l’avait fait, mais j’ai considéré que ça ne faisait pas le poids, à ce moment-là, face à d’autres événements. »
C’est la limite de mon petit travail : comme tous les journalistes, Guetta parle d’abord des pays dont on parle, ceux qui sont « dans l’actualité », aussi mouvante soit la définition qu’on donne à ce mot. Mais je reste convaincu que sur une si longue période et un si grand nombre de textes, mon exploration du « monde de Bernard Guetta » a malgré tout du sens.
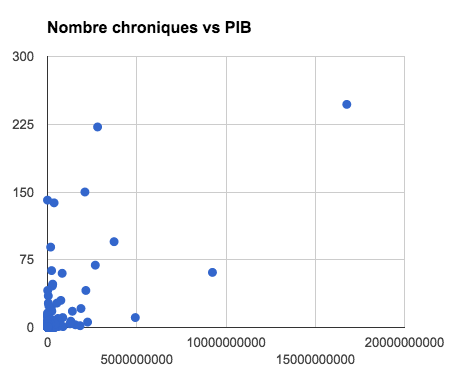
Plus un pays est riche, plus il est cité
Si on met de côté l’actu, quel critère peut expliquer qu’un pays s’impose ou non sur cette drôle de mappemonde ? En croisant ces relevés avec les données de la Banque mondiale, j’ai cherché des corrélations. J’ai fait chou blanc avec la superficie, la population, le PIB par habitant ou le nombre de décès dans des conflits armés.
En revanche, plus un pays est globalement riche, et plus il a de chances d’être cité dans les chroniques de Guetta – pour les matheux, le coefficient de corrélation est de 0,64. Ce n’est pas illogique : une économie importante va souvent de pair avec des dépenses militaires significatives et une diplomatie plus active.
La liste des personnalités les plus citées réserve elle peu de surprises, même si on notera que Jacques Delors et Charles de Gaulle font de fréquentes apparitions – le premier est plus souvent cité qu’Hugo Chavez.
Enfin, je me suis aussi intéressé au contexte dans lequel ces pays et ces personnalités étaient citées, grâce à un logiciel de « lexicométrie ». J’ai cherché par exemple les adjectifs les qualifiant, notamment ceux qui peuvent dénoter un jugement de valeur voire un parti-pris (par exemple, « populiste » pour Chavez ou « intransigeant » pour Poutine).
L’Europe et le « divorce » des Européens
On peut voir ainsi que Guetta associe très souvent le mot « Europe » (et ses dérivés) au mot « divorce », dans des phrases comme : « Le divorce croissant entre les Européens et l’Europe menace jusqu’à l’idée même d’unité européenne. » Européiste convaincu, il a fait activement (outrageusement pensent certains, comme Acrimed) campagne pour le oui au référendum sur le traité constitutionnel de 2005.
Mais ces quelques coup de sonde n’ont pas donné grand chose : les « cooccurrences » (soit les mots qu’on relève souvent au voisinage d’un autre dans le texte) détectées m’ont semblé assez neutres – en y passant plus de temps, un spécialiste ferait peut-être davantage de trouvailles.
La preuve d’une prudence très diplomatique dans le choix des formulations ? Bernard Guetta explique en tout cas « sa très grande méfiance à l’égard de mots qui ne veulent plus rien dire, comme islamiste » : « Je préfère utiliser un langage plus précis, un mot qui décrit ce qui se passe. »
Mis à jour le 8 mai à 8h20. Erreur d’unité dans le classement et la carte corrigée, merci à @florenchev de l’avoir signalée.
Mis à jour le 11 mai à 8h30. Erreur dans le nombre de citations d’Erdogan, merci à Sibel Fuchs de l’avoir signalée sur Facebook.
Dustin Hoffman et Robert Redford dans « Les Hommes du président »
Imaginez la scène. Un homme vous a contacté et donné rendez-vous au dernier sous-sol d’un parking mal éclairé. En jetant des regards par dessus son épaule, les doigts tremblants, il vous confie un gros disque dur, en expliquant qu’il y a là-dedans des documents explosifs pour la multinationale dans laquelle il travaille. Puis il disparaît sans demander son reste.
Vous voilà en possession de données qui seront, peut-être, à l’origine du scoop de votre carrière. Tout journaliste web a rêvé de vivre un tel moment – d’ailleurs, Edward, si jamais tu passes par ici, sache que j’ai une clé PGP, moi, pas comme cet étourdi de Glenn Greenwald.
Problème : « Il est rare qu’un lanceur d’alertes se pointe après avoir rassemblé toutes les informations utiles aux journalistes dans un texte de quinze pages », a rappelé le spécialiste en datajournalisme Friedrich Lindenberg lors de son intervention au Festival de journalisme de Pérouse la semaine dernière.
C’est plus probablement dans un fatras de milliers de documents au format PDF, Excel, Word, Powerpoint et leurs équivalents qu’il va vous falloir fouiller, si vous voulez y dénicher l’information exclusive qui vous vaudra la gloire.
Heureusement, de plus en plus d’outils existent pour vous aider dans ce genre de situations, souvent mis au point pour les journalistes à l’occasion des précédentes fuites de grande ampleur. Lindenberg en a décrit six, que voici :
DocumentCloud pour héberger les données et gérer leur accès
Capture d’écran du site de de DocumentCloud.
Plutôt que naviguer à l’aveugle dans le disque dur qu’on vous a refilé, avec le gestionnaire de fichiers de Windows ou de Mac OS, DocumentCloud permet de stocker l’ensemble des documents, de les parcourir plus confortablement, de les annoter et même de les intégrer ensuite à vos articles.
Comme vous risquez d’avoir besoin d’aide dans vos démarches, vous pourrez aussi donner accès à vos précieux fichiers à d’autres utilisateurs ou groupes d’utilisateurs, en gérant finement les autorisations des uns et des autres.
Pour créer votre compte sur ce service, il vous faudra cependant demander un accès à l’équipe qui a fondé ce service, en présentant votre projet. Une fois installé, DocumentCloud peut aussi servir à centraliser les documents utilisés par toute votre rédaction, et peut-être opérer des rapprochements entre deux enquêtes séparées.
Attention quand même : si vos documents sont vraiment explosifs, du genre à faire sauter la République, vous éviterez d’utiliser ce service directement en ligne, mais vous l’installerez plutôt « en local », soit sur votre ordinateur seulement – sachant que dans un cas pareil, bien d’autres précautions s’imposent.
Overview pour faire parler les gros ensembles de documents
Capture d’écran du site d’Overview.
L’outil a été mis au point à l’origine par l’agence AP et la Knight Foundation pour explorer les documents de l’armée américaine sur la guerre en Afghanistan diffusés par Wikileaks.
Ses algorithmes opèrent des rapprochements entre les concepts qu’il a détecté dans les millions de fichiers que vous lui avez fait avaler (jusqu’aux sons au format MP3), en créant des liens entre ces différents clusters. Pour explorer les e‑mails piratés de Sony, Overview se révèle ainsi beaucoup plus efficace que l’outil mis en ligne par le site de Julian Assange.
Il permet aussi de taguer vos recherches pour les retrouver plus facilement, et propose plusieurs modes de visualisation. « L’équipe qui s’en occupe est très intéressée par les nouveaux outils d’analyse et les nouveaux challenges, explique Lindenberg. Ils vous aideront dans vos recherches, et peuvent améliorer une fonctionnalité en quelques heures seulement. » Overview peut aussi être installé en local.
Crowdata pour que les internautes vous aident dans votre quête
Capture d’écran du site de Vozdata.
Après avoir passé vos week-ends et vos nuits à chercher la pièce maîtresse perdue dans le gros tas d’octets qu’on vous a mis sur les bras, vous avez un coup de mou ? Il est temps de demander à Internet de vous venir en aide.
Crowdata est l’outil qui a servi au quotidien argentin La Nacion à lancer Vozdata, une opération de crowdsourcing pour laquelle chaque internaute était invité à examiner un des 6 500 documents comptables fournis par les sénateurs afin y chercher d’éventuelles irrégularités. Inventeur de cet exercice de transparence, le Guardianle reproduit chaque année pour les notes de frais des députés britanniques.
Crowdata peut se brancher directement sur DocumentCloud, pour vous faciliter encore la tâche. Mais vous aurez sans doute besoin de l’aide d’un développeur pour l’installer, et faire de tous vos lecteurs deds enquêteurs en pantoufles.
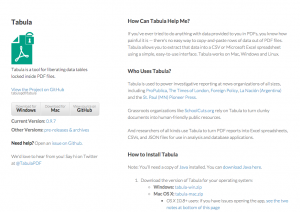
Tabula pour extraire des tableaux dans des documents PDF
Capture d’écran du site de Tabula.
Souvent utilisé pour la diffusion d’études ou de rapports, le PDF est un format qui empoisonne la vie des datajournalistes, parce qu’il n’est pas vraiment conçu pour qu’on puisse réutiliser les divers éléments composant un document.
Avec Tabula, il suffit de sélectionner le tableau qui vous intéresse pour les lignes et les colonnes et les manipuler dans un tableur. Selon Lindenberg, Tabula est l’une des meilleures solutions pour cette tache, mais elle n’est pas parfaite : des décalages entre les colonnes peuvent apparaître et corrompre votre série de données.
C’est pour ça qu’il teste souvent plusieurs outils pour un même tableau, avant d’opter pour celui qui s’en sort le mieux (selon mon expérience, Adobe Acrobat fait ça plutôt bien, mais il est payant).
Aleph pour croiser vos données avec d’autres sources
Capture d’écran du site d’Aleph.
Pour tirer cette affaire au clair, vous aurez peut-être besoin de croiser vos précieux fichiers avec d’autres sources existantes. C’est ce que propose Aleph, outil encore expérimental mais avec lequel vous pouvez jouer pour chercher si la personnalité ou l’entreprise sur laquelle vous travaillez apparaît ailleurs, grâce à des représentations graphiques.
Utiliser davantage le recoupement avec des bases déjà en lignes, c’est devenu « la croisade personnelle » de Lindenberg :
«Il faut que les journalistes d’investigation acceptent de dire à des gens comme moi qui sont les personnes ou entreprises qui les intéressent, cette information restant confidentielle, bien sûr.
Dès que j’ai cette liste, je peux mener des recherches dans une grande quantité de documents déjà publiés, et activer des notifications dès qu’une nouvelle correspondance est trouvé. Mais les journalistes ne lâchent pas facilement ce genre d’info, il faut encore que je trouve un moyen de les convaincre. »
La salle de contrôle des vols spatiaux de la Nasa en 2005 (Nasa).
Ça fait partie de ces conférences où l’on se surprend à applaudir et à encourager mentalement l’intervenant pendant son exposé, tant ce qu’il dit paraît pertinent.
Stijn Debrouwere, spécialiste des statistiques des sites de médias, parlait jeudi au Festival international de journalisme de Pérouse. Voici une retranscription que j’espère fidèle, mille excuses d’avance si j’ai déformé un propos ou raté une idée importante
Stijn Debouwere. Je travaille sur les statistiques des sites d’information depuis quatre à cinq ans, j’ai commencé dans des médias locaux (télévisions et quotidien), ensuite j’ai rejoint le service d’analyse des données du Guardian. Récemment, j’ai réalisé une mission pour le Tow Center sur ces sujets.
J’ai pu voir des statistiques de beaucoup d’entreprises différentes, et je me suis aperçu que les mêmes problèmes apparaissent un peu partout.
Quand on parle des statistiques d’un site, bien souvent l’image mentale qui se forme est celle d’une salle de contrôle sophistiquée, comme celle de la Nasa à Houston, où chaque employé a plein de moniteurs différents.
Travailler de cette façon a bien marché pour la Nasa : dans le cas d’Apollo 13, c’est même ce qui a permis de ramener les astronautes sur Terre malgré les défaillances, grâce à toutes les données à disposition que les ingénieurs ont pu analyser pour déterminer la marche à suivre.
Ça peut aussi marcher dans des start-ups ou des entreprises centrées sur les nouvelles technologies, on voit qu’elles réussissent à lever des fonds ou réaliser un bon chiffre d’affaires en utilisant correctement les indicateurs dont elles disposent.
Mais ça ne marche pas aussi bien pour les médias. On voudrait des outils simples, objectifs et qui aident à la décision, et ce qu’on a bien souvent, c’est du « bruit », des fausses pistes et un miroir aux vanités.
Et quand on utilise mal les statistiques, ça peut avoir des conséquences néfastes, comme ces posts sur Facebook où on « optimise » les titres pour chasser les clics, avec des formules du type « vous n’allez pas croire ce qui arrive à ce chat après ça ».
Selon le consultant américain Peter Drucker, la meilleure façon de supprimer toute perception est d’inonder les sens avec des stimuli. Ça veut dire que les services que vous utilisez doivent être configurés pour vous donner uniquement l’information que vous souhaitez avoir. Sinon, vous ne pourrez rien faire.
Dans les rédactions aujourd’hui, les métriques se sont peu à peu accumulées : Google Analytics, Facebook Insights, Twitter Analytics… Ce sont de bons outils, mais on se retrouve avec des dizaines de tableaux de bord différents, tous mis à jour constamment.
Il faut se poser des questions de base. Pourquoi est-ce qu’on regarde des stats ? Parce qu’on veut pouvoir en tirer des conclusions. Mais en réalité, peu de rédactions sont capables de réagir immédiatement à une donnée, par exemple faire un article quand un sujet est en train de buzzer.
Je croise des journalistes très accros à Chartbeat[service de statistiques sur la fréquentation de son site mesurées en temps réel, ndlr], il faudrait leur passer sur le corps pour leur enlever ça. Mais quand je leur demande à quoi ça leur sert vraiment, ils ne savent pas trop quoi répondre.
Et vous avez sûrement déjà assisté à une réunion où quelqu’un débarque avec une grande idée, un changement à faire sur le site, en ayant au préalable sélectionné précisément LA donnée qui va dans son sens, en ignorant tout le reste.
Sans parler des biais qui peuvent se glisser. Il y a quelques années, YouTube a fait un gros effort pour optimiser les pages, et accélérer le chargement des vidéos. Quand ils ont mis ces changements en production, ils se sont rendus comptes que les métriques allaient dans le mauvais sens, qu’en fait le temps de chargement des vidéos avait tendance à augmenter.
C’est une donnée cruciale pour eux, donc ils avaient un vrai problème. En analysant davantage, ils se sont aperçus qu’ils avaient tellement bien travaillé que des internautes avec des connexions lentes ou de vieux ordinateurs s’étaient mis à regarder des vidéos, alors qu’avant ils ne pouvaient pas du tout le faire.
Et ce sont ces nouveaux utilisateurs qui faisaient plonger les statistiques, parce que les vidéos mettaient beaucoup de temps à se charger pour eux – mais au moins, ils pouvaient les voir. Les mêmes données qui les ont induits en erreur leur ont permis de comprendre vraiment ce qui se passait, en les examinant de plus près.
Sachant tout ça, qu’est-ce qu’on peut faire pour mieux travailler les statistiques ?
1. Avant de regarder vos statistiques, regardez votre site
D’abord, il faut garder en tête qu’il y a plein de changements possibles sans même avoir à les consulter, il suffit d’ouvrir les yeux.
On sait par exemple que les newsletters sont une façon de gagner du trafic et d’avoir des lecteurs plus fidèles. Regarder votre site : combien de temps vous faut-il pour vous inscrire à la newsletter ?
Même remarque pour le placement des boutons de partage des réseaux sociaux : est-ce qu’ils sont accessibles, est-ce qu’ils sont assez visibles ? Ce sont des choses très simples à corriger.
Un autre conseil que je donne, c’est d’avoir une check-list à remplir avant toute publication d’un contenu.
Je m’aperçois que dans beaucoup de sites, il y a toute une partie du contenu qui n’est jamais mis en avant nulle part, ni sur la page d’accueil, ni sur les réseaux sociaux. Il faut passer par une sous-sous-rubrique pour y accéder. Même leur auteur ne tweete pas un lien vers son article une fois publié !
Il faut avoir une stratégie interne pour chaque publication, par exemple programmer des tweets avec outils comme Buffer pour couvrir les différents fuseaux horaires. Vérifier que l’article comporte bien des liens externes et internes, c’est aussi important, et c’est le genre de choses qu’on peut mettre dans une check-list. Vous voyez, il y a zéro technologie en jeu ici, juste du bon sens.
2. Ne vous contentez pas des valeurs proposées par défaut
Ensuite, il faut mesurer les bonnes choses. Trop souvent, on se contente des métriques qui sont proposées par défaut. Si Google Analytics vous propose trois mesures quand on charge la page (par exemple « sessions », « utilisateurs » et « pages vue »), ça ne veut pas forcément dire que ce sont ces trois métriques-là que vous devez surveiller.
Au début, il était beaucoup question de pages vues, ensuite de « reach », après d’engagement. Je me souviens qu’un type a publié une tribune un jour sur Medium pour expliquer qu’il fallait vraiment regarder le temps passé sur le site, que c’était ça l’important.
Des clients ont commencé à m’appeler et à me dire qu’ils voulaient faire pareil, et je leur ai dit : « Vous allez vraiment changer complètement de stratégie, juste parce qu’un type a écrit ça sur Medium ? »
3. Regardez les ratios plutôt que les totaux
Il faut s’intéresser davantage aux ratios qu’aux valeurs absolues. Le nombre de pages vues, par exemple, ça ne m’intéresse pas forcément si je le prends isolément. En revanche, si je compare avec le nombre d’articles publiés dans la journée, ça peut devenir intéressant.
Si le nombre de pages vues aujourd’hui est le double de celui d’hier et que le nombre d’articles publiés a doublé aussi, ce n’est pas une bonne nouvelle, ça veut dire qu’on n’a pas amélioré la visibilité de chaque contenu. Regarder le nombre de pages vues par auteur, ça peut être bien aussi.
Des rédacteurs en chef me disent : « On ne publie pas beaucoup le week-end parce qu’on n’a pas beaucoup de visiteurs le week-end. » Mais en fait, c’est parce qu’ils publient peu le week-end qu’ils n’ont pas beaucoup de trafic le week-end – en tout cas, c’est une hypothèse que je ferais…
Si on regarde le nombre de pages vues par article, à chaque heure du jour ou bien pour chaque jour de la semaine, on peut sortir de ce type de problème d’œuf et de poule.
4. Suivez moins d’indicateurs mais suivez-les mieux
Il faut aussi réduire le nombre de métriques surveillées. Se concentrer sur la fidélité des lecteurs par exemple, c’est un bon réflexe, mais ça peut vous mettre dans des situations surprenantes. Mettons qu’un de vos articles devienne viral : ça va faire chuter vos indicateurs de fidélité, parce que vous allez attirer soudain des gens qui ne viendront qu’une fois chez vous, pour un seul contenu.
Ce que je préfère observer, c’est l’évolution des frequent users, les lecteurs réguliers, une notion utilisée par les entreprises technologiques : par exemple, on regarde l’évolution de ceux qui ont passé au moins dix sessions dans les trois derniers jours. Et là, on se rend compte que c’est une courbe beaucoup plus stable, les pics de trafic sont gommés.
Quand Facebook s’est lancé, on ne pouvait s’y enregistrer qu’avec e‑mail hébergé par une série d’universités américaines. Ça faisait donc très peu d’utilisateurs en valeur absolue. Mais les fondateurs ont senti qu’ils tenaient un service intéressant quand ils se sont aperçus que les gens restaient très longtemps quand ils venaient.
Dans les rédactions, on ne mesure pas assez la qualité des contenus. Une expérience simple à réaliser, c’est de demander aux journalistes de donner une note de 1 à 10 au contenu qu’il vient de publier. On peut demander aux lecteurs de le faire aussi. Au final, cette statistique obtenue de façon artisanale est aussi importante que les chiffres de Google Analytics.
5. Cherchez un bon compromis plutôt qu’un objectif isolé
Plutôt que des cibles ou des objectifs, il faut chercher des sweet spots, de bons compromis. « Surperformer » peut être aussi mauvais pour un site que « sous-performer ».
Mettons que vous vouliez absolument multiplier le nombre de contenus en ligne. Vous allez vous organiser pour que vos auteurs publient 50 articles chaque semaine. Votre trafic va augmenter, OK, ça peut sembler super. Mais la qualité de ce qui est produit va plonger, et si vous ne la mesurez pas, vous ne le saurez jamais.
Du coup on va plutôt se dire : peut-être qu’on peut réduire un peu la longueur des articles, ce qui nous permettrait d’en publier un peu plus, sans que le lecteur ne se sente lésé.
J’entends dire : « Notre objectif est d’attirer un million de visiteurs en plus en provenance des réseaux sociaux. » OK, mais quel effet ça va avoir sur les autres métriques ?
Sur le Web, on s’est vite aperçu qu’il n’y avait pas de corrélation entre la longueur d’un article et le nombre de visites qu’il reçoit. Ce n’est pas parce que le texte est plus long qu’il sera plus vu.
Du coup, certains ont dit : il faut faire court, pour faire plus de pages vues. D’accord, mais on en fait quoi ? La plupart des sites ont déjà trop d’inventaire, les campagnes publicitaires ne sont pas assez nombreuses pour remplir tous les emplacements.
Si vous ne le monétisez pas, ce trafic supplémentaire, c’est un trafic-poubelle : en vérité, vous n’en voulez pas ; ce que vous voulez, ce sont des lecteurs qui reviennent souvent.
Les statistiques doivent être au service d’un projet, ce ne sont pas des buts en soit.
Quand je parle à des gens des entreprises de technologie, ils se demandent comment utiliser leurs statistiques pour améliorer le service qu’ils rendent aux internautes ? Mais côté médias, la question qu’on me pose c’est : quelle est la statistique que je dois cibler ? Ils ne veulent pas faire grandir le site, le rendre meilleur. Juste faire monter des chiffres.
6. Faites des tests sur la durée avant de décider
Il ne faut pas hésiter à faire des expériences,comme celle des articles evergreen de Vox : ils ont pris des contenus forts publiés plusieurs mois avant, ils les ont mis à jour et republié. Et ils ont gagné beaucoup de pages vues, pour des contenus qui étaient enterrés dans les archives. Certains lecteurs les avaient ratés, d’autres les avaient oubliés, dans tous les cas ils étaient contents de les lire.
Slate aussi tente des choses : par exemple, ils demandent à leur rédacteur de faire du trafic whoring pendant toute une journée ; chasser les clics avec un maximum de contenus très attractifs. En échange, ils vont avoir deux ou trois jours sans contraintes, pour creuser un sujet.
Même chose avec Quartz, et leur théorie sur les contenus de longueur moyenne, qu’il faut éviter de publier, pour privilégier les articles soit plus courts, soit plus longs [la Quartz curve, ndlr].
Il faut cependant laisser ces expériences vivre assez longtemps. Un seul article sur une nouvelle thématique ne suffit pas à savoir s’il faut lancer une nouvelle rubrique, pourtant je l’ai vu faire aussi.
D’abord parce que Google Analytics pratique l’échantillonnage : les calculs ne sont pas forcément fait sur l’ensemble des stats, mais sur un échantillon, pour que ça aille plus vite. Du coup un changement ponctuel aura moins d’impact.
Mais surtout parce qu’il y a un tas de facteurs extérieurs qui peuvent influer énormément, comme l’auteur de l’article ou l’heure de publication.
7. Montrez à vos journalistes des mesures qui ont du sens pour eux
Une bonne pratique, c’est aussi de proposer la bonne métrique à la bonne personne. Souvent, la frustration ressentie face aux statistiques vient du fait qu’on n’a pas vraiment de prise sur les chiffres qu’on vous donne.
Par exemple, améliorer la visibilité de l’abonnement à la newsletter, c’est un objectif intéressant pour designer, mais pas pour le journaliste, qui ne peut rien faire pour changer ça.
Pour un journaliste, savoir le nombre de visites que son article a fait, ça n’est pas très utile finalement, puisqu’il a déjà terminé son travail.
Même chose si vous mettez un grand panneau lumineux dans la rédaction avec des informations du type : « les pages vues ont baissé de 5% par rapport à hier ». Le journaliste va se dire : « OK, mais qu’est-ce que je peux y faire ‚à mon niveau ? » Au final, ça aura des effets néfastes sur sa motivation.
8. Analysez vous-même vos données
Quand vous regardez vos statistiques, sachez que le bouton « Exporter » est votre meilleur ami. Récupérer les données brutes et les analyse vous-mêmes dans un tableur de type Excel, ça va vous permettre de creuser davantage et de garder le plus pertinent.
Au final, les stats en temps réel ont leur intérêt, c’est cool à regarder, ça donne l’impression que vous êtes dans la salle de contrôle de la Nasa. Mais régler des petits problèmes sur le site, cocher des cases sur une check-list, c’est peut-être moins prestigieux, cependant c’est ça qui fait la différence. Et pour les médias il y a de gros gains à faire avec un minimum d’efforts, dans certains cas il suffit de se baisser pour les ramasser.
L’économiste Robert Solow a décrit dans les années 70 un paradoxe : les entreprises disposaient d’ordinateurs, de tableurs (c’était nouveau à l’époque), mais pourtant la productivité ne s’est pas vraiment améliorée à cette période.
C’est un peu pareil pour les médias : les statistiques ont le potentiel de vraiment améliorer les choses, mais ce n’est pas le cas pour le moment. D’où l’intérêt d’écouter Peter Drucker, et d’arrêter de se laisser submerger par elles.
Mis à jour le 17/4 à 21h30. Quelques précisions et menus changements grâce aux retours du conférencier que j’ai reçus par e‑mail. Une erreur corrigée : c’est YouTube et non Facebook qui a eu des stats surprenantes après avoir optimisé le chargement des vidéos.
Stijn Debrouwere a eu la gentillesse d’y ajouter une série de liens pour ceux qui souhaitent prolonger leur réflexion sur le sujet :
Ça fait un petit moment que j’avais envie de me coltiner aux données du service de location de logements entre particuliers Airbnb, après avoir vu la série de cartes réalisées par Tom Slee dans différentes villes du monde.
Et voilà que le site du Temps publie une enquête sur les loueurs d’Airbnb à Genève, en montrant qu’une part importante des offres publiées proposent des appartements qui ne sont pas ou plus habités à l’année.
Plus la couleur d’un appartement est foncée, plus son tarif est élevé. Pour voir des exemples de prix pratiqués, zoomez en double-cliquant, approchez la souris sur un des cercles ou tapez-le.
Autrefois modèle de « l’économie du partage », Airbnb est ainsi accusé de « siphonner » le marché locatif, les propriétaires y multipliant les locations courte durée plutôt que de choisir un occupant pérenne.
Un scraper pour récupérer les données
Pour mener leur enquête, les journalistes ont récupéré les données au moyen d’un scraper, une sorte de robot qui va visiter une à une les pages du site pour y récupérer des informations repérées au préalable. dans le code source.
Avec quelques manipulations simples sur les données ainsi récupérées, ils ont pu repérer de gros loueurs – telle Jasmina, qui gère 120 biens sur Airbnb – puis les faire témoigner.
Jean Abbiateci, co-auteur de cette enquête avec Julie Conti, raconte cette démarche pas à pas dans le blog Data Le Temps et a eu la bonne idée de mettre à disposition le script mis au point pour Outwit Hub, le logiciel qui a servi au scraping, que j’utilise aussi.
J’ai ainsi pu récupérer un échantillon de 2 000 offres parisiennes, proposant uniquement la location d’un logement entier (et pas d’une chambre privée ou une chambre partagée). Ça m’a servi à dresser la carte publiée en haut de cet article.
J’ai veillé à répartir les annonces choisies pour couvrir un maximum de terrain et obtenir une carte harmonieuse – par exemple, je n’ai gardé que 27 points dans le IIIe arrondissement, alors que c’est celui où les offres sont les plus nombreuses (3,2 par hectare).
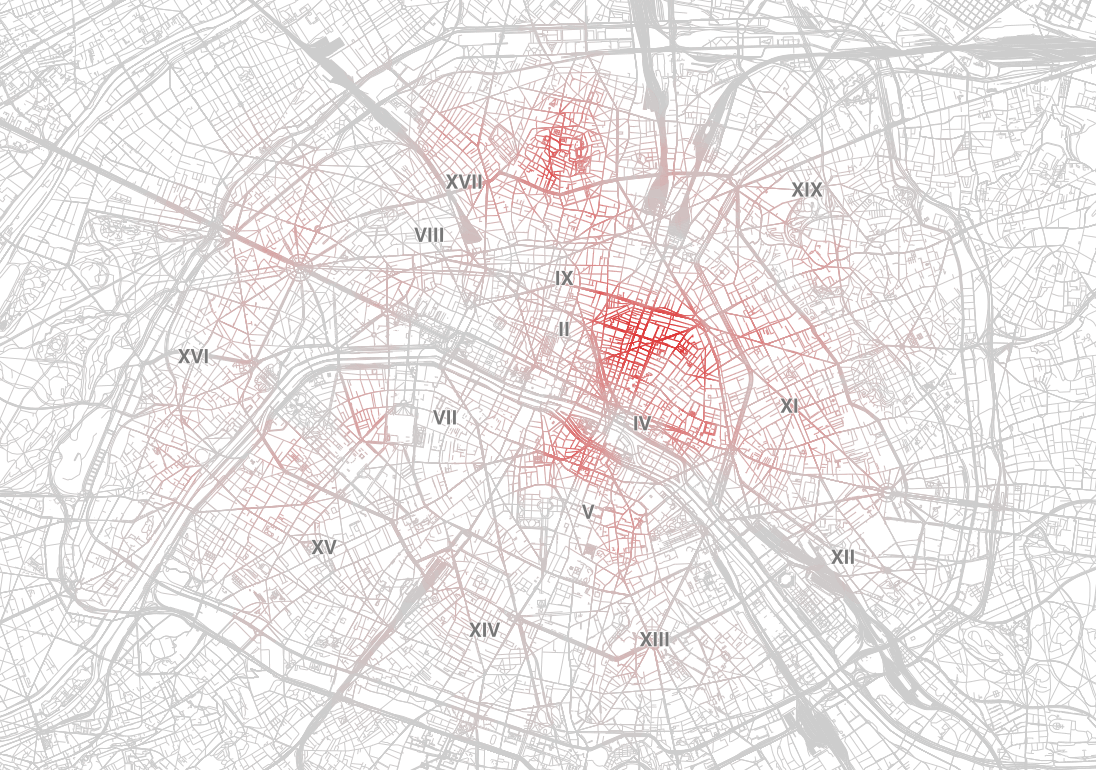
Si on en tient pas compte de ce critère, la répartition des offres dans la capitale est en effet très inégale, comme le montre cette carte de chaleur (heat map).
Carte de chaleur des annonces Airbnb à Paris. Plus la couleur d’une rue est vive, plus il y a d’annonces dans le quartier.
« Au final, ta carte va être la même que celle du marché de l’immobilier à Paris », m’a prévenu un confrère qui travaille dans un newsmagazine bien connu pour ses marronniers sur le sujet.
Sa remarque est vraie, mais pas entièrement : un arrondissement peut être plus cher sur Airbnb (c’est le cas du VIIIe et du VIe) que dans une agence traditionnelle, ou au contraire moins cher (le XIXe et le XVIIIe notamment).
Et les gros poissons, alors ? Je ne donnerai pas leur profil, histoire de ne pas faciliter le travail du fisc ou du service dédié de la mairie de Paris, mais j’ai repéré des utilisateurs qui ont plusieurs dizaines d’annonces sur le site – des loueurs qui ne ressemblent donc pas beaucoup à ceux en photo sur la page d’accueil, mais plus à des professionnels ayant trouvé un bon filon.
Le phénomène semble assez circonscrit cependant : en cherchant parmi plus de 2 500 annonces, je n’ai trouvé que 9 inscrits avec plus de cinq annonces.
Mais il est possible que les professionnels d’Airbnb se créent plusieurs profils pour gérer leur pool d’annonces et dans ce cas, ils ne peuvent être détectés par cette méthode.
Bonus pour ceux qui ont lu jusqu’ici. Afin d’avoir une idée des expressions les plus utilisés pour convaincre les touristes, voilà un nuage de mots créés avec les titres des annonces de l’échantillon.
Les mots les plus utilisés dans les titres des annonces d’Airbnb à Paris.
J’ai présenté les tableaux de façon interactive avec le plug-in JQuery Datatables.
Comme chacun de ces services peut vous intéresser, je reviens pas à pas dans cet article sur la méthode utilisée, en donnant des liens vers les fichiers de données obtenues. N’hésitez pas à réutiliser ces dernières pour d’autres travaux, et tenez-moi au courant de vos trouvailles dans les commentaires.
A plusieurs reprises, j’ai fait des choix qui m’ont semblé cohérents avec l’objectif de ce projet. Que vous soyez wikipédien ou journaliste, vous aurez sans doute envie de les discuter, ce que je vous encourage fortement à faire, je suis là pour ça.
1. Bâtir un échantillon avec CatScan
La première difficulté, c’était de trouver une série de notices Wikipédia pertinentes.
J’ai d’abord pensé à programmer Outwit Hub pour en collecter de façon totalement aléatoires, en utilisant par exemple le lien « Explorer au hasard » de l’encyclopédie. Mais mon « robot » s’est vite perdu dans des fiches sans lien avec l’actualité ou dans diverses pages de listes.
J’ai alors découvert CatScan et je m’en suis servi pour obtenir les liens de notices figurant dans toute une série de catégories et sous-catégories. En partant la catégorie Evenement de Wikipédia, j’ai sélectionné les sous-catégories suivantes (elles-mêmes divisées en une multitude de sous-catégories :
Evénement en cours
Evénement à venir
Evénement récent
Journée commémorative ou thématique
Massacre
Evénement historique en météorologie
Salon
Marche
Controverse
Festival
CatScan m’a renvoyé une liste de 16741 notices (sur un total de plus de 1,6 million publiés sur la Wikipédia en français, soit environ 1%) sur des sujets très variés. La taille de cette liste m’a paru suffisante – au-delà, les différents logiciels dont je me suis servi n’aurait de toute façon pas pu fonctionner correctement.
2. Programmer un scraper avec Outwit Hub
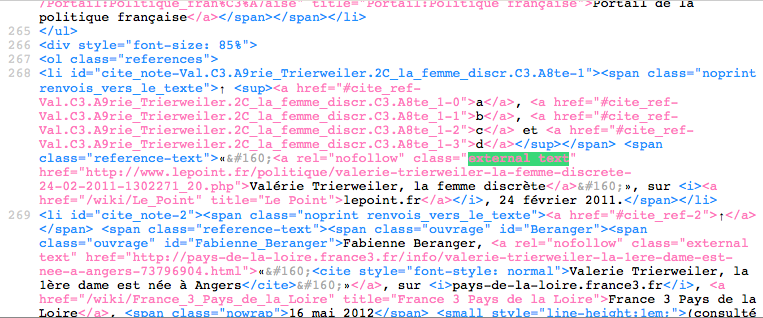
Bien que l’interface de ce logiciel de scraping soit intimidante (euphémisme), Outwit Hub n’est pas si compliqué à utiliser, une fois qu’on a digéré les tutoriels de base. Il suffit d’identifier où se trouvent dans le code source les informations qu’on recherche et comment elles sont structurées en langage HTML.
En l’occurrence, les liens se trouvant dans les parties qui m’intéressaient (« Notes et références » et « Voir aussi » notamment) sont dans des balises liens (« a ») portant la classe CSS « external text ».
Capture d’écran de Outwit Hub
Il suffit alors de créer un « extracteur »,en indiquant à Outwit Hub les chaînes de caractères se trouvant juste avant et juste après l’information ciblée. Par exemple, pour l’URL externe :
<a class="external text" href="
et
">
Pour extraire plusieurs informations à la fois (l’URL, mais aussi le nom de domaine et le texte du lien), j’ai cependant dû construire une expression régulière. Sans vous faire un cours complet sur ces trucs-là (ce dont je serais bien incapable), sachez qu’on les croise un peu partout (de Yahoo Pipes à Adobe Indesign en passant par les différents languages de programmation).
Pour un non-développeur, c’est un peu pénible à apprendre, mais ça rend bien des services, ça en vaut donc la peine. Après avoir pas mal transpiré, j’ai fini par bâtir l’expression suivante (sûrement perfectible, d’ailleurs) :
Outwit Hub était alors paré pour le moment le plus agréable du projet, celui où l’ordinateur travaille à votre place : il a suffit de lui demander de passer cet extracteur sur chaque page de l’échantillon, puis d’exporter tous les résultats obtenus dans un gros fichier CSV (20 Mo).
3. Nettoyer les résultats avec Open Refine
Quand vous souhaiter intervenir sur de gros fichiers de données, les fonctionnalités les plus courantes (comme Rechercher / Remplacer) ne suffisent pas.
C’est là qu’Open Refine (anciennement Google Refine) se révèle particulièrement utile, parce qu’il permet de faire via une interface graphique très bien fichue des manipulations de tables qui doivent se faire sinon via des lignes de commande.
Là encore, il faut accepter de se plonger dans les tutoriels et les pages d’aide pour apprendre à effectuer les opérations souhaitées, mais c’est du temps bien investi, croyez-moi.
Dans le cadre de ce projet, je me suis servi de Google Refine pour présenter proprement chaque donnée dont j’avais besoin :
l’URL de la notice Wikipédia « scrapée »
l’URL du lien externe repéré
le nom de domaine du lien externe repéré (par exemple, slate.fr)
le texte du lien (souvent le titre de l’article)
J’ai aussi réparti ces noms de domaines en deux catégories : « Actu » et « Autres » (pour tous les liens vers des sites annuaires, institutionnels, ou personnels).
C’était l’étape la plus fastidieuse : pour éviter d’y passer la journée et de faire planter Open Refine, je me suis limité aux médias cités au moins 30 fois dans l’échantillon.
Certains sites dans cette liste avaient un statut ambigu : j’ai conservé ceux proposant à la fois des articles et des statistiques ou pages de référence (par exemple, Allociné), et d’exclure les purs annuaires (comme IMDB).
J’ai aussi pratiqué quelques regroupements, pour les sites possédant plusieurs sous-domaines (par exemple, en fusionnant les liens vers www.lefigaro.fr et elections.lefigaro.fr en lefigaro.fr).
On approche du but : en important le CSV contenant tous les liens vers des sites de médias dans une feuille de calcul Google Sheets, il ne reste plus qu’à créer un rapport de tableau croisé dynamique chargé de compter le nombre de liens pour chaque nom de domaine.
Cette information est également disponible dans Open Refine, mais j’avais besoin d’une présentation par cellules pour pouvoir en faire un graphique dans la foulée.
(Je n’ai jamais vraiment compris comment fonctionnaient vraiment ces rapports, et je suis bien embêté quand je dois expliquer leur fonctionnement lors de formations. Je me contente d’essayer diverses combinaisons de lignes, de colonnes et de valeurs pour obtenir le résultat souhaité, ce qui finit toujours par arriver à force d’essais.)
5. Faire le graphique avec Datawrapper
Je ne sais pas s’il est possible de tomber amoureux d’un logiciel ou d’un service web, mais si c’est le cas, je dois confier une passion sans doute excessive pour Datawrapper – selon moi, Mirko Lorenz, son programmeur, a déjà sa place réservée au paradis des développeurs.
Un copié/collé des données de Google Sheets et quelques réglages dans une interface merveilleusement bien pensée, et zou, le graphique est prêt.
6. Un tableau filtrable avec Datatables
A ma connaissance, il existe peu d’outils accessibles pour présenter de longues séries de données proprement à l’intérieur d’un article. Le plug-in JQuery Datatables fait ça vraiment très bien, mais il faut être suffisamment à l’aise en HTML, en CSS et en JQuery pour s’en servir.
J’ai donc récupéré le flux Json du Google Sheet pour bâtir dynamiquement le tableau contenant les 23 014 liens vers des sites de médias, et activé Datatables une fois la table terminée.
7. Des échantillons sur des thématiques
Pour continuer à explorer l’encyclopédie, j’ai choisi des thèmes plus précis et repéré des catégories (et leurs sous-catégories) de notices portant sur le sport, la politique, la Bretagne et la BD.
J’ai fait subir le traitement décrit ci-dessus aux liens externes ainsi repérés (ça va beaucoup plus vite la deuxième fois).
« Wikipedian protester », strip de XKCD (CC-BY-NC)
Les médias français et la version francophone de Wikipédia entretiennent une relation compliquée. La fiabilité de l’encyclopédie collaborative a longtemps été mise en doute par des chroniqueurs et éditorialiste, mal à l’aise face à l’absence de « comité éditorial » ou d’instance dirigeante bien identifiée.
Certains journalistes n’hésitent pas à « vandaliser » des notices pour mieux appuyer leur démonstration, comme pour un reportage d’Envoyé spécial diffusé en novembre 2012 et qui avait hérissé le poil des Wikipédiens ou pour le livre La Révolution Wikipédia, publié sous la direction du chroniqueur littéraire Pierre Assouline en 2007.
Pourtant, les journalistes utilisent quotidiennement Wikipédia pour leurs recherches d’information, même s’ils en connaissent souvent mal le fonctionnement et le complexe système d’autorégulation. En formation, j’ai souvent dû prendre le temps de faire l’anatomie d’une notice, de la liste de sources en bas d’article à l’onglet « Discussion », en passant par la comparaison des différentes versions.
La « référence nécessaire », règle d’or de l’encyclopédie
Et les Wikipédiens eux-mêmes se servent largement des sites d’information pour sourcer le contenu de leurs notices. Les rédacteurs doivent en effet respecter une règle fondamentale : l’absence de travaux inédits dans le texte des notices. Tout savoir qui y est référencé doit s’appuyer sur une source existante, qu’il s’agisse d’un livre, d’une page officielle ou, bien souvent, d’un article de presse.
Un porte-clés Wikipédia (Cary Bass-Deschenes/CC-BY-SA)
C’est pour cette raison qu’on croise régulièrement la mention « (Réf. nécessaire) » [et non « citation nécessaire, merci Gilles, ndlr] dans le contenu d’une page, signe qu’un contributeur vigilant a édité la page pour signaler que l’information mentionnée n’était pas correctement sourcée.
En 2012, l’écrivain américain Philip Roth a pu mesurer toute l’intransigeance de cette règle quand il a tenté de modifier la notice d’un de ses romans, correction refusée par un administrateur de la Wikipédia anglophone. Un épisode qu’il a raconté dans le New Yorker.
L’existence d’un nombre d’articles suffisant traitant d’une personnalité ou d’un phénomène étant d’ailleurs un critère important pour juger de la « recevabilité » d’un nouvel article – ce qui avait amusé Daniel Schneidermann lors d’une une émission d’Arrêt sur images sur ce sujet sensible.
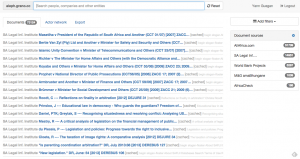
Mais quelles sont leurs sources privilégiées ? J’ai mené une petite enquête en me basant sur un échantillon de plus de 16 500 fiches contenant en tout plus de 100 000 liens externes. Je reviens pas à pas sur la méthode utilisée dans un autre article de ce site, où je liste aussi l’ensemble des données utilisées – sachez juste que mon ordinateur a beaucoup ressemblé à ça ces dernières heures :
Voilà donc le top 50 des sites d’actu dont le contenu est le plus souvent cité en référence dans Wikipédia :
Si au lieu d’un échantillon « généraliste » de fiches, on se cantonne à des sélections resserrées, on peut voir comment cette liste de médias de référence évolue thème par thème – n’hésitez pas à me contacter ou à laisser un commentaire si vous souhaitez que j’explore d’autres thématiques.
Enfin, si vous êtes journaliste, vous avez peut-être envie de savoir quels contenus de votre média ou de son concurrent font désormais référence, peut-être pour l’éternité – c’est quand même plus chic que d’être cité dans un tweet de Nadine Morano, non ?
Vous pouvez chercher votre média et les notices dans lequel il est cité dans la liste complète des liens de l’échantillon « généraliste », soit 1% du total des fiches publiées sur Wikipédia. Si le tableau ne se charge pas, vous pouvez retrouver la liste complète dans cette Google Sheet.